
Towards the Next Generation of Recommender Systems
27 Jun 2021 | Recommend추천 시스템에 대한 survey 논문.
추천 시스템 분야의 개요를 제시하고, 세 가지 클래스로 분류되는 현재 세대의 추천 알고리즘에 대해 설명함
- content based
- collaborative
- hybrid
추천 시스템의 역사는 인지 과학, 근사 이론, 정보 검색, 예측 이론 등으로 거슬러 올라 갈 수 있다.
본격적으로 연구가 시작된건 1990년대 중반 이후 CF(collaborative filtering)에 대한 첫 번째 논문이 등장한 이후 이고, 레이팅 구조에 명시적으로 의존하는 추천 문제에 포커스를 맞추기 시작하면서 독립적인 연구 분야로 발전했다.
일반적으로 추천 문제는 사용자가 보지 못한 아이템에 대한 평가를 추정하는 문제로 볼 수 있다.
직관적으로 이 추정치는 사용자가 이전에 다른 아이템에 부여한 레이팅과, 다른 기타 정보를 기반으로 한다.
레이팅이 지정되지 않은 아이템에 대한 레이팅을 추정할 수 있으면 추정 레이팅이 가장 높은 아이템을 사용자에게 추천할 수 있다. 이를 다음과 같이 공식화 할 수 있다.
- C : set of all users
- S : set of all possible items
- u : $C \times S \rightarrow R$
추천 시스템의 중요한 문제점은 유틸리티 함수인 $u$ 가 전체 $C\times S$ 공간에 정의되지 않는다는 점이다.
즉, $u$는 subset에서 전체 공간으로 외삽(extrapolation) 되어야 한다.
이러한 외삽은 구체적인 예시로 알고있는 레이팅에서 알 수 없는 레이팅으로의 외삽이 있으며 다음 테이블의 공집합을 채우는 것으로 볼 수 있다.
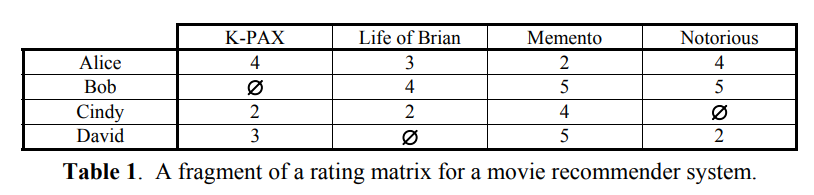
외삽은 일반적으론 두 가지 프로세스로 수행되는데
- 유틸리티 함수를 정의하고 성능을 경험적으로 검증하는 휴리스틱을 지정함.
- MSE와 같은 특정 성능 기준을 최적화하는 유틸리티 함수를 추정함.
이를 통해 알 수 없는 레이팅(공집합)을 추정하고 나면 해당 사용자에 대한 모든 예측 레이팅 중에서 가장 높은 레이팅을 선택해서 추천하거나 Top N개의 아이템을 뽑아서 추천하는식으로 사용함.
레이팅이 지정되지 않은 아이템에 대해서 ML, Approximation theory, 다양한 휴리스틱 등을 사용해서 추정할 수 있다.
이제 앞서 말한 세 가지 추천 알고리즘 중 하나에 대해서 살펴보자.
Content-Based Methods
컨텐츠 기반 추천 방법은 유저 $c$에 대한 아이템 $s$의 유틸리티 $u(c,s)$는 유저가 아이템 $s$와 ‘유사한’ 아이템 $s_i \in S$에 할당한 유틸리티 $u(c, s_i)$를 기반으로 추정한다.
컨텐츠 기반 추천 접근 방식은 정보 검색 및 정보 필터링 연구에 뿌리를 두고 있다.
또한, 사용자의 취향, 선호도, 요구 사항에 대한 정보가 포함된 사용자 ‘Profile’을 사용하여 기존의 정보 검색에 비해 개선되었다.
포멀하게 Content(s)를 아이템 프로필 즉, 아이템을 특징 짓는 속성 집합이 되도록한다. 일반적으로 아이템(컨텐츠)에서 피처 집합을 추출하여 계산되며 추천 목적으로 아이템의 적합성을 결정하는데 사용된다.
대부분의 컨텐츠 기반 추천 방법은 텍스트 기반 아이템을 추천하도록 설계되었으므로 이러한 시스템의 컨텐츠는 일반적으로 ‘‘키워드’‘로 묘사된다.
문서 $d_j$ 에서 단어 $k_i$의 “importance”(or “informativeness”)는 여러가지 다른 방식으로 정의할 수 있는 가중치 메저 $w_{ij}$로 결정된다.
정보 검색에서 키워드 가중치를 지정하는 잘 알려진 메저 중 하나는 TF-IDF 이다.
- $N$ : 사용자에게 추천 가능한 총 문서의 수
-
$n_i$ : 특정 키워드 $k_i$가 나타난 문서의 빈도 수 (df)
- $f_{i,j}$ : 키워드 $k_i$가 포함된 문서 $d_j$의 수
- $f_{z,j}$ : 문서 $d_j$에 모든 키워드 $k_z$가 나타난 빈도 수 (정규화 용으로 사용하는 듯)
따라서 문서 $d_j$의 컨텐츠는 $Content(d_j) = (w_{1j}, \cdot\cdot\cdot ,w_{kj})$ 로 정의된다.
앞서 언급했듯 콘텐츠 기반 시스템은 사용자가 과거에 좋아했던 것과 유사한 아이템을 추천한다. 특히 사용자가 이전에 평가한 아이템과 다양한 후보 아이템을 비교해서 가장 잘 맞는 아이템을 추천한다.
좀 더 포멀하게 ContentBasedProfile(c)를 이 유저의 취향과 선호도를 포함하는 유저 c의 프로필이 되도록 한다. 이러한 프로필은 이전에 사용자가 평가한 아이템의 내용을 분석해서 얻으며, 일반적으로 정보 검색에서 키워드 분석 기술을 사용하여 구성된다.
예를 들어, ContentBasedProfile(c)는 가중치 벡터 $(w_{c1,\cdot\cdot\cdot, w_{ck}})$로 정의할 수 있다.
여기서 각 가중치 $w_{ci}$는 유저 $c$에 대한 키워드 $k_i$의 importance를 나타내며 다양한 기술을 사용하여 개별적으로 평가된 컨텐츠 벡터에서 계산될 수 있다.
여기서 언급된 다양한 기술들은 Rocchio 알고리즘, 베이즈 분류기, Winnow 알고리즘 등이 있다.
컨텐츠 기반 시스템의 유틸리티 함수는 다음과 같이 정의된다.
\[u(c,s) = score(ContentBasedProfile(c), Content(s)) \tag{5}\]유저 $c$의 ContentBasedProfile(c)와 문서 $s$의 컨텐츠를 모두 TF-IDF 벡터 $w_c, w_s$로 나타낼 수 있다.
따라서 유틸리티 함수는 코사인 유사도와 같은 휴리스틱으로 다음과 같이 정의할 수 있다.
- K : 시스템의 총 키워드 수
결과적으로 코사인 또는 관련 유사성 측정을 하는 추천 시스템은 $w_s$가 유저가 선호하는 키워드가 있는 기사에 더 높은 유틸리티 함수 u(c, s)를 할당하고, 선호하는 키워드에 대한 가중치가 더 낮은 아이템에 더 낮은 유틸리티를 할당한다.
Limitation of content-based method
- 텍스트 문서가 아닌 다른 도메인에서 automatic feature extraction에 내재된 문제가 있다.
- 예를 들면 멀티미디어 데이터(graphical images, audio streams, video streams)
- 두 가지 다른 아이템이 동일한 피처로 표시되는 경우 구분할 수 없다.
- no serendipity - 이미 평가된 항목과 유사한 추천으로 제한되기 때문에 신선한 추천을 받을 수 없다.
- 컨텐츠 기반 시스템이 사용자의 선호도를 실제로 이해하려면 유자가 충분한 수의 아이템을 평가해야한다.
Collaborative Method
컨텐츠 기반과의 차이점은 비슷한 성향을 가진 유저 A, B가 존재할 때 A가 선호하지만 B는 아직 모르는 아이템이 있을 때 그 아이템을 추천하는 방식으로 볼 수 있다.
즉, 문자 그대로 여러명의 취향을 반영해서 추천을 진행하는 시스템이라고 볼 수 있다.
또한 컨텐츠 기반이 TF-IDF를 통해 나타내는 피처의 가중치를 통한 유사도를 측정하는 방식이라면,
협업 필터링은 유저가 실제로 매긴 레이팅을 바탕으로 유사도를 측정한다.
협업 필터링은 크게 두 가지 방식으로 나뉜다.
- Memory-Based(or heuristic-based)
- 유저들에 의해 이전에 매겨진 평점을 바탕으로 예측(추천)하는 시스템
- Model-Based
- ML모델을 통해 데이터의 패턴을 파악해서 추천하는 방식.
Memory-Based Collaborative Method
알 수 없는 레이팅 $r_{c,s}$에 대하여 다른 유저의 같은 아이템 s에 대해 레이팅을 집계해서 계산한다.
- $\hat C$ : 아이템 s에대해 매긴 평점이 유저 c와 가장 유사한 N명의 유저 집합
위 aggregatrion function에 대한 다음과 같은 예시가 존재한다.
\[r_{c,s} = \frac1N \sum\limits_{c'\in \hat C} r_{c',s}\] \[r_{c,s} = k \sum\limits_{c'\in \hat C} sim(c,c')\times r_{c',s}\] \[r_{c,s} = \bar r_c + k \sum\limits_{c'\in \hat C} sim(c,c')\times (r_{c',s} - \bar r_{c'})\]- $k$ : normalizing factor , 보통 $1/ \sum\limits_{c’\in\hat C}\vert sim(c,c’)\vert$을 사용한다.
- $\bar r_c$ : 유저 c의 레이팅 평균, $1/\vert S_c\vert \sum\limits_{s\in S_c} r_{c,s},\ where \ S_c = { s\in S \vert r_{c,s} \neq \emptyset}$
두 번째 수식 같은경우 전형적인 weighted sum 형태의 수식이다.
그러나 유저들의 레이팅 스케일이 다른 경우를 고려하지 못해서 세 번째 수식에선 레이팅의 절댓값이 아닌 편차로 계산해서 이 문제를 해결한다고 한다.
레이팅 스케일이 다른 문제를 해결하는 또 다른 방법에는 preference-basded filtering이 존재한다.
이 경우 레이팅에 집중하는 것이 아닌 유저의 선호도를 파악하는데 중점을 둔다.
$sim(c,c’)$ 을 구하는 다양한 방법이 존재함. 논문에서는 cosine based, correlation based로 구분하고 아래의 두 식을 사용함.
- cosine similarity
- pearson correlation
서베이 논문이다 보니 다양한 알고리즘을 얘기해주는데, 퍼포먼스 향상을 위해 코사인 기반, 상관계수 기반의 확장으로 다음과 같은 기법들을 얘기해준다.
- default voting
- inverse user frequency
- case amplification
- weighted-majority prediction
위의 예시중 디폴트 보팅은 결측 레이팅을 그대로 두는 것이 아닌 디폴트 레이팅을 가정하고 채우는 경우가 성능이 더 좋다는 것을 경험적으로 보여준다.
memory-based method 또한 두 가지 방식으로 나뉘는데,
- user-based
- item-based
item-based 방식이 user based보다 계산 성능도 좋고 추천 퀄리티도 좋다고 한다.
Model-Based Collaborative Methods
우리가 흔히 생각하는 모델(ML)을 학습시키는 용으로 레이팅을 사용한다.
확률적 모델에는 두 가지가 존재하는데
- Cluster Model
- Bayesian Model
클러스터 방식의 장점이자 단점이 single cluster 이다. 즉, 단점으로 보면 더 좋게 그룹화 될 수 있는걸 방해하는 것이고,
좋게 말하면 serendipity가 생긴다는 것이다.
모델 기반 방법이 메모리 기반 방식 보다 성능이 더 좋다고 한다. (물론 경험적인 증거밖에 존재하지 않음.)
정말 다양한 모델 기반 방법이 존재한다.(K-means, Gibbs Sampling, Bayesian, linear regression, maximum entropy model …etc)
심지어 shani et al. 에서 MDP를 이용한 추천 시스템도 제안했다.
그외에도 latent semantic analysis, latent dirichlet allocation 등 다양한 확률 기반의 접근 방식이 존재한다.
kumar et ad. 에서 제한된 조건에서의 단순한 협업 필터링 알고리즘이 유틸리티 측면에서 가장 효과적인 알고리즘이라는 것을 입증했다.
모델 기반과 메모리 기반을 결합한 접근 방식이 더 좋은 추천을 제공하는 것을 경험적으로 입증했다.
Limitation of collaborative methods
- 컨텐츠 기반 방식과 동일하게 새로운 유저에대한 문제점이 존재함.
- 이는 후에 서술할 hybrid system으로 해결 가능함.
- 다른 대안으로는 item popularity, item entropy, user personalizagtion에 기반한 전략이 존재함.
- 새로운 아이템에 대한 문제점도 존재함.
- 상당한 수의 유저가 새 아이템을 평가할 때 까지 추천시스템은 해당 아이템을 추천하기 어려움.
- 희소성 문제도 존재함.
- 이를 해결하기 위해 유저간의 유사도를 구할 때 유저 프로필 정보를 사용하는 방법이 있음.
- 이러한 확장을 ‘demographic filtering’ 이라고 함.
- 그 외에도 SVD 같은 차원 축소 알고리즘을 사용하는 접근 방식도 존재함.
Hybrid System
여러 추천 시스템은 CF, CB를 결합하여 사용하는 하이브리드 접근 방식을 사용할 수 있음.
이는 위의 두 가지 방식에 한계를 피하는데 도움이 된다.
다음과 같은 4가지 타입의 하이브리드 시스템이 존재한다.
- CB, CF를 각각 구현한 뒤 예측을 결합
- 개별적으로 추천 시스템에서 얻은 아웃풋에 linear combination 또는 보팅을 사용하여 하나의 최종 추천으로 결합.
- 혹은 개별 추천 모델 중 ‘quality’가 좋은 모델을 metric 기반으로 하나 뽑아서 사용함.
- CB의 특성을 CF에 결합
- CF 자체가 sparse한 데이터를 사용하기 때문에 content-based profile을 사용하여 이를 회피함.
- CF의 특성을 CB에 결합
- content-based profile 그룹에 dimension reduction 기술을 사용하는 방식(LSA)
- 당연히 기존의 term vector(TF-IDF) 사용할 때 보다 성능 좋아짐.(빈도수가 아니라 의미까지 고려하니까.)
- 둘 다 통합하는 일반적인 단일 모델을 구성
- single rule-based classifier에서 content based 및 collaborative 특성을 사용하는 방식
Comments