
Stand-Alone Self-Attention in Vision Models
30 May 2021 | VisionSummary
- 기존의 convolution layer를 self-attention layer로 변경해도 비전 모델에서 comparable한 성능을 보임.
- self-attention은 convolution보다 더 적은 파라미터 수와 FLOPS를 가짐.
- 그러나 stem(모델의 앞단)에는 convolution layer를 쓰고 후반부에는 attention을 쓰는 것이 더 좋은 성능을 보임.
최초로 비전 모델에 attention을 도입한 실험은 아니지만, 이 논문에서 나온 여러가지 실험이 꽤나 유의미 하다고 생각됩니다. 그리고 논문 자체에서도 특별한 점은 없고 실험을 통해 보여주는 것들이 많기 때문에 실험을 위주로 설명하겠습니다.논문에서 성능 향상의 원인이라고 언급하는 것들은 다음과 같습니다.
- Spatial Extent
- Positional Encoding Type
- Attention Type
- Attention Stem Type
Spatial Extent
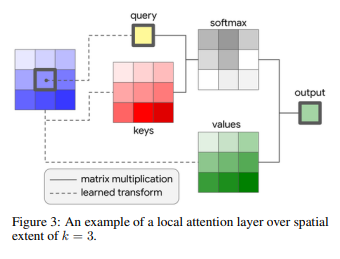
보시는 것 처럼 그냥 컨볼루션 필터의 크기와 비슷하게 받아들일 수 있습니다.
다만 컨볼루션과 다른 점이라면 Spatial Extent 파라미터인 $k$를 키워도 파라미터 수는 항상 고정이라는 것입니다.
여기서 생각 해볼 수 있는 점은 모델 후반부에 attention layer를 사용하여 Spatial Extent를 크게 가져가서 pixel들의 상관관계를 capture하는 식으로 사용하면 잘 동작하지 않을까? 라는 것입니다. 물론 논문에서도 $k$를 키울수록 성능이 좋았지만 feature size, attention head의 사용 등의 하이퍼 파라미터에 따라 달라질 수 있다고 합니다.
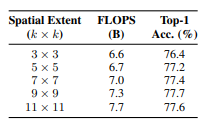
Positional Encoding Type & Attention Type
단순히 픽셀 값을 이용하여 attention을 사용할 경우 위치에 대한 정보가 담겨있지 않게 됩니다. 이런 경우에 비전 태스크에서 표현력이 제한되므로 본 논문에서는 Positional Enconding을 위해 Relative Postion이라는 것을 사용합니다.(픽셀의 절대 위치를 기반으로 하는 Sinusoidal 임베딩을 사용할 수 있지만 상대 위치 임베딩이 정확도가 더 좋아서 사용했다고 합니다.)
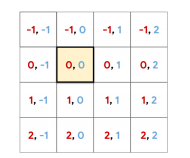
Realtive Position이 특별한 것은 아니고 위 그림처럼 특정 pixel을 잡고 row, column offset을 정해주는 방식을 사용합니다.
이 정보를 attention에 넣어주게 되면 기존의 수식
\[y_{ij} = \sum\limits_{a,b \in N_k(i,j)} softmax_{ab}(q_{ij}^Tk_{ab})v_{ab}\tag{1}\]이 다음과 같이 변경됩니다.
\[y_{ij} = \sum\limits_{a,b \in N_k(i,j)} softmax_{ab}(q_{ij}^Tk_{ab} + q_{ij}^Tr_{a-i,b-i})v_{ab}\tag{2}\]따라서, $N_k(i,j)$ 에서 쿼리와 키 사이의 유사도를 측정하는 로짓은 키의 content와 쿼리로 부터 키의 상대적 거리에 의해 변화됩니다.
softmax의 내부수식중 앞부분 $q_{ij}^Tk_{ab}$은 쿼리로 부터 구성된 내용이고, $q_{ij}^Tr_{a-i,b-i}$은 쿼리로 부터 키의 상대적인 거리를 나타냅니다.
이러한 Realtive Encoding을 사용하는 것이 전체적인 성능이 가장 높은 것을 실험을 통해 확인할 수 있습니다.
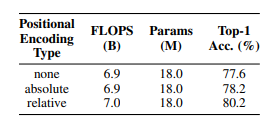
또한 수식 (2)에서 사용한 content-relatvie interaction이 중요한 역할을 한다는 것을 아래 표에서 보여줍니다.
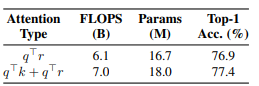
Attention Stem Type
이 부분의 핵심은 논문의 섹션 3.2에 나와있는 다음 문장입니다.
At the stem layer, the content is comprised of RGB pixels that are individually uninformative and heavily spatially correlated. This property makes learning useful features such as edge detectors difficult for content-based mechanisms such as self-attention
즉, Stem 부분에서 Content는 개별적으로 정보를 가지지 않으며, 공간적으로 연관된 RGB 픽셀로 구성됩니다.
이러한 경우 Self-attention은 각 토큰의 상관관계를 파악하는 네트워크이지만, 이미지에서 각 R, G, B픽셀은 단독으로 의미를 가지지 않습니다. 따라서 초기 이미지의 경우 각 픽셀에 대한 Attention은 사실상 의미가 거의 없어지고 Convolution을 사용하는 것이 더 낫다는 얘기입니다.
따라서 이를 위해 기존의 attention을 수정해서 사용해야 했고, distance based information을 이용했습니다.
새로 만든 value는 다음과 같습니다.
\[v_{ab} = (\sum\limits_m p(a,b,m)W_V^m)x_{ab}\] \[p(a,b,m) = softmax_m((emb_{row}(a) + emb_{col}(b))^Tv_m)\]$p(a,b,m)$은 CNN과 유사하게 주변 픽셀들로 부터 scaler의 weight dependect를 학습한다.
최종적으론 이를 spatially-aware attention이라고 부르는데, 이를 사용할 때 성능이 가장 좋았다.
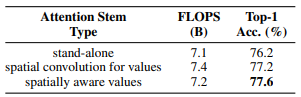
Results
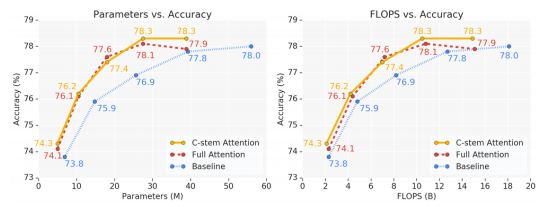

보는 것 처럼 Conv-stem + Attention의 조합이 FLOPS도 적으면서 성능이 좋은 것을 확인할 수 있습니다.
Comments