
Continuous control with deep reinforcement learning
17 Dec 2020 | rlSummary
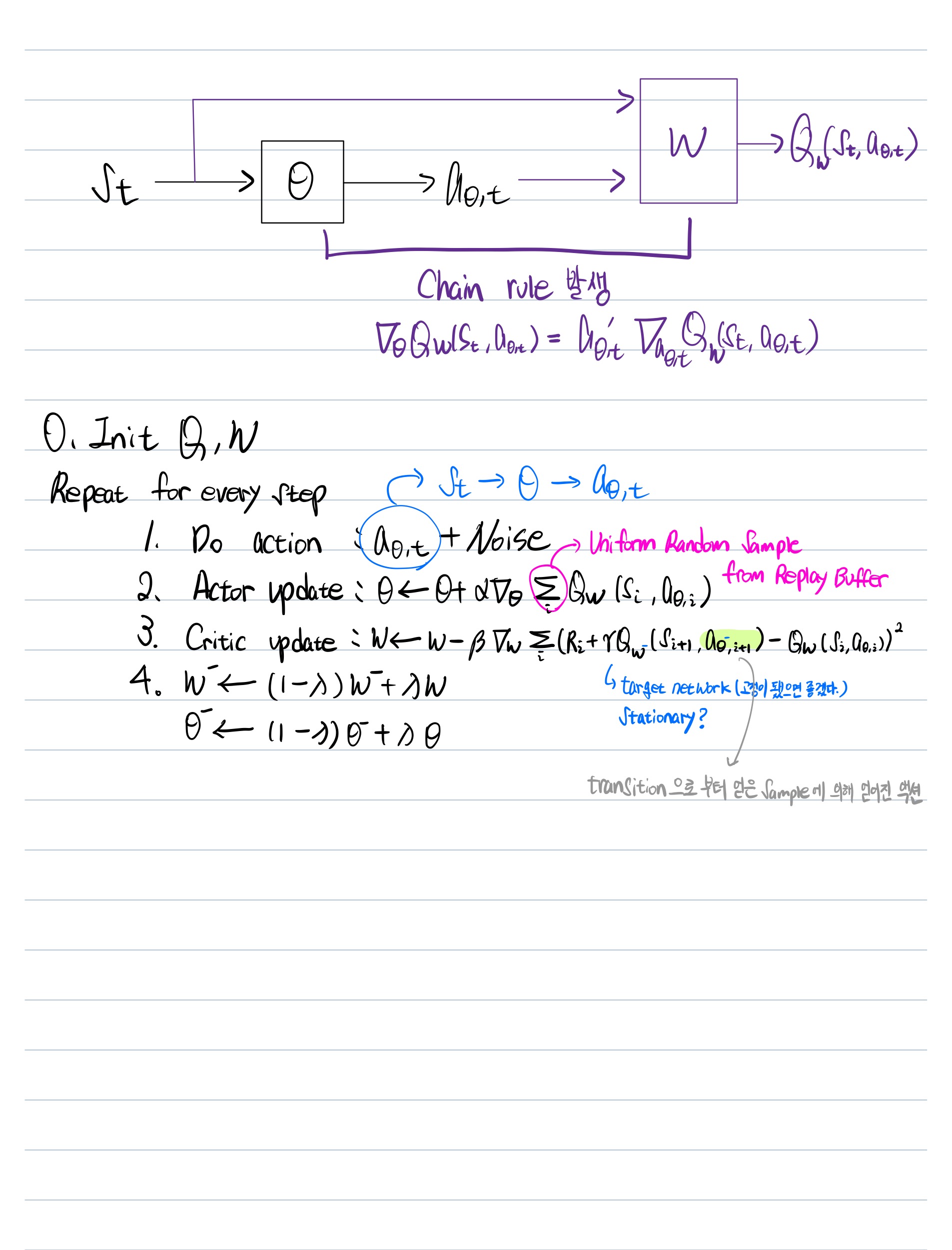
- (Deterministic) Policy Gradient 사용
- NN(non linear function approximator)로 actor-critic을 구현하는 것은 어려움(unstable and challenging)
- DQN에서 얻을 수 있는 insight
- Experience Replay
- Target Network사용
- Modified using ‘soft’ target updates
- Batch Normalization
- Actor-Critic의 Off-policy.ver


Comments