
A Survey of Model Compression and Acceleration for Deep Neural Networks
15 Dec 2020 | compression모델 압축 및 가속에 대한 분야는 크게 네 가지 카테고리로 나눌 수 있음
- Parameter Pruning and Quantization
- Low-rank factorization
- Transferred/compact convolutional filters
- knowledge distillation
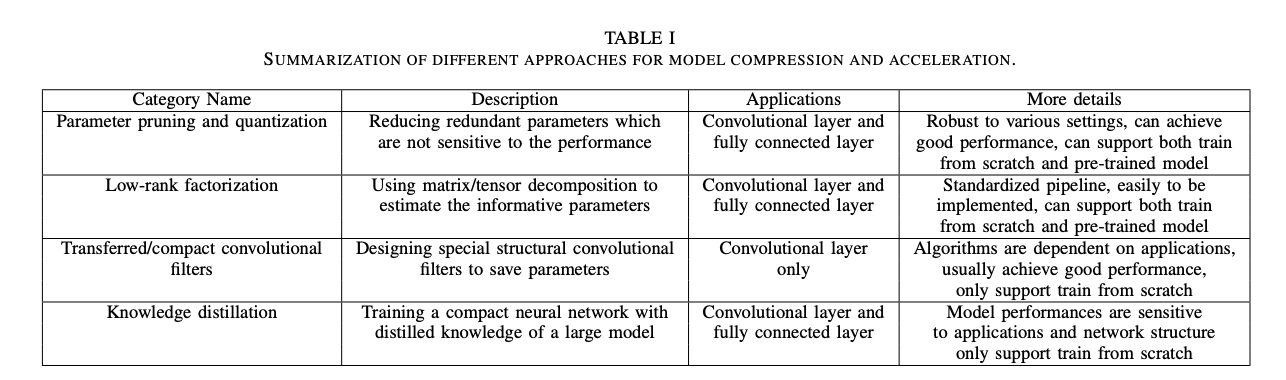
Parameter Pruning and Quantization
모델 파라미터의 redundancy및 중요하지 않은 부분(퍼포먼스에 영향을 주지 않는)을 제거하는 방법.
다양한 설정에 대해 robust하며, 좋은 퍼포먼스를 달성할 수 있고, scratch 부터 학습하거나 pre-trained 모델에 적용 가능.
convolution layer, fully connected layer 모두에 사용 가능하다.
Parameter Pruning and Quantization은 또 세 가지 카테고리로 나눌 수 있다.
A. Quantization and Binarization
- Compressing Deep Convolutional Networks using Vector Quantization
- Quantized Convolutional Neural Networks for Mobile Devices
위 두 논문은 k-means scalar quantization을 사용함.
8-bit 양자화가 정확도 손실을 최소화 하면서 상당한 속도 향상을 가져올 수 있음을 보여줌.
stochastic rounding 기반 CNN에서 16-bit fixed-point를 사용하여 분류 정확도의 손실을 거의 없애며 메모리 사용량과 부동 소수점 연산을 크게 줄임.
가중치 공유를 이용하여 링크 가중치를 양자화한 다음, 양자화된 가중치와 codebook에 허프만 코딩을 적용하여 비율을 더욱 낮춤.
즉, 중복 연결을 제거하고 가중치를 양자화한 다음 허프만 코딩을 사용하여 양자화된 가중치를 인코딩한 방법을 사용.
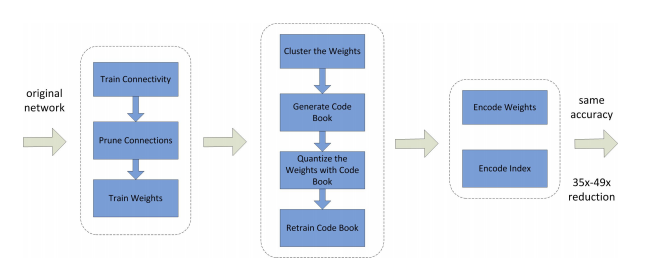
위 그림에서 볼 수 있듯, 정상적인 네트워크 훈련을 통해 연결을 학습한 다음, 소규모 연결을 잘라내는 것으로 시작함.
마지막으로 네트워크는 나머지 희소 연결에 대한 최종 가중치를 학습하도록 재학습됨.(Qunatization based method로 SOTA 달성한 페이퍼)
헤시안 가중치를 사용하여 네트워크 매개변수의 중요성을 측정할 수 있음을 보여주며 클러스터 파라미터에 대한 평균에서 헤시안 가중치 양자화 에러를 최소화 할 것을 제안함.
Bianrization의 경우 아래의 모델들이 존재하고(셋 다 인용수 높음),
- *BinaryConnect: Training Deep Neural Networks with binary weights during propagations
- *Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1
-
*XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
- Deep neural networks are robust to weight binarization and other non-linear distortions
위 논문에서는 역전파로 훈련된 네트워크가 바이너리 가중치를 포함한 특정 가중치가 왜곡에 대해 탄련적일 수 있음을 보여줌.
이진화의 단순 행렬 근사와 정확도 손실을 해결하기 위해 diagonal 헤시안 근사를 사용하는 proximal 뉴턴 알고리즘을 제안함.(이진 가중치에 대한 손실을 직접 최소화 하는)
확률적으로 가중치를 이진화하고 히든 스테이트 계산의 곱셈을 significant changes로 변환하여 훈련 단계에서 부동 소수점 곱셈에 걸리는 시간을 줄임.
저 정밀도 네트워크 학습을 위한 half-wave 가우시안 양자화를 제안함.
B. Network Pruning
아래 세 가지 논문은 고전 논문임(1990년대)
프루닝에 대한 초기 접근법 Biased Weight Decay
- Advances in neural information processing systems 2
- Second order derivatives for network pruning: Optimal Brain Surgeon
위 방법은 손실함수의 헤시안을 기반으로 연결 수를 줄임.
이러한 고전 논문들은 프루닝 방법이 Weight Decay와 같은 규모 기반 프루닝 보다 더 높은 정확도를 제공한다고 제안함.
뉴런 간의 중복성을 조사하고 중복 뉴런을 제거하기 위해 data-free 프루닝 방법을 제안함.
전체 네트워크에서 파라미터 및 연산을 줄이기 위해 제안함
파라미터 공유를 위해 가중치를 해시 버킷으로 그룹화하기 위해 저렴한 해시 함수를 사용하는 hashedNets 모델을 제안함
하나의 간단한 훈련 절차에 양자화와 프루닝을 모두 포함하는 소프트 가중치 공유에 기반한 간단한 정규화 방법을 제안함.
구조화된 Brain-damage를 달성하기 위해 컨볼루션 필터에 그룹 희소성 제약을 부과함. 즉, 그룹 방식으로 컨볼루션 커널의 엔트리를 프루닝함.
훈련 단계에서 필터가 감소된 컴팩트 CNN을 학습하기 위해 뉴런에 대한 그룹-희소 정규화가 도입됨.
사소한 필터, 채널 또는 레이어를 줄이기 위해 각 레이어에 구조화된 희소성 정규화를 추가함
필터 레벨 프루닝에서 위의 모든 작업은 l1 or l2 norm 정규화를 사용함.
l1-norm을 사용하여 중요하지 않은 필터를 선택하고 제거함.
Comments