
A3C
02 Dec 2020 | rlSummary
actor : Environment + Agent (action을 통한 경험을 누적함.)
learner : 쌓인 경험으로부터 학습시키는 주체.
Actor-Learner thread가 여러대 존재해서 병렬적으로 만든 뒤 한 곳에 잘 모아서 학습함.
각각의 스레드에서 그래디언트를 계산해서 중앙의 Global Network로 보내줌.
Asynchronous의 의미는 한 스레드에서 업데이트 하는 동안 다른 스레드는 경험 누적 그리고 업데이트 완료 후 다른 스레드에서 업데이트 하면 또 나머지 스레드는 경험 누적하는 방식을 의미함.
각각의 스레드에 exploration , exploitation을 잘하는 애들을 다양하게 놔두면 성능이 좋다는 것도 논문에 언급됨.
Contribution
RL 알고리즘의 scale-up 방법 제시
- off/on policy, value/policy-based(generalize)
- Experience Replay 대신 병렬적인 actor가 decorrelation을 가능하게 해줌.(RL을 SL(iid)으로 학습하기 위해서 떠올린 방법론)
- Gpu대신 Cpu 스레드 사용
- Super Linear(n개의 actor-learner면 n배 이상의 학습 속도를 보임.)
atari game에서 SOTA 찍음.
논문에서 다루는 4가지 알고리즘
- One-step Q-learning
- N-step Q-learning
- One-step SARSA(Q-learning의 On-policy.ver)
- A2C(On)
Abstract
딥러닝 컨트롤러의 최적화를 위해 비동기적 gradient descent를 사용하는 Deep reinforcement learning을 위한 개념적으로 간단하고 가벼운 프레임 워크를 제안함.
네 가지 표준 강화 학습 알고리즘의 비동기적 변형을 제시하고, 병렬화된 액터-러너가 훈련에 안정화 효과를 가져와 네 가지 방법 모두에 대해 컨트롤러를 성공적으로 훈련시킬 수 있음을 보여줌.
actor-critic의 변형으로 사용한 방법은 Gpu대신 Cpu환경에서 절반의 시간동안 훈련하면서 아타리 게임 도메인에서 SOTA를 달성함.
또한, asynchronous actor-critic이 시각적 입력을 사용하여 임의의 3D미로를 탐험하는 새로운 작업 뿐만 아니라 다양한 연속 모터 제어 문제에서도 성공하는 것을 보여줌.
Introduction
DNN은 RL알고리즘을 수행하기에 충분한 표현력을 제공하지만 근본적으로 두 도메인의 조합은 불안정함.
그래서 알고리즘을 안정화 시키기 위한 다양한 방법이 제안되었는데, 이러한 접근 방법들은 공통된 개념을 강조하는데, 온라인 RL 에이전트에 의해 처리되는 관측된 데이터의 시퀀스는 고정적이지 않고 상관관계가 매우 높음.
DQN에서 보여준 방법인 Experience Replay가 대표적인 상관관계를 없애는 방법중 하나. 혹은 uniform sample도 좋은 방법임. 그런데 이런 방식으로 메모리를 모으는 것은 안정성을 높일 수는 있지만 동시에 제한적일 수도 있음. 아타리 게임과 같은 도메인에서 전례없는 성공을 거뒀지만, 몇 가지 단점을 보임(실제 상호작용 당 더 많은 메모리와 계산을 요구함. 또한 off-policy가 기반이 되어야 쓸 수 있음.)
이 논문에서는 위의 방법 보다 일반화 가능한 방법을 제공함. Experience Replay 대신 여러 환경에서 여러 에이전트를 비동기적으로 동시에 실행함. 이 병렬 처리는 에이전트의 데이터를 고정된 프로세스로 분리함. 이런 간단한 개념은 SARSA, N-step TD, Actor-Critic과 같은 off Policy & on Policy 모두에서 사용 할 수 있음.
Asynchronous RL Framework
병렬 구조로 인해 얻는 이득
- reduction in training time that is roughly linear in the number of parallel actor-learners
- we no longer rely on experience replay for stabilizing learning we are able to use on-policy reinforcement learning methods such as Sarsa and actor-critic to train neural networks in a stable way
추가적으로 Policy Entropy를 사용함.
\[Entropy(H(p(x)) = \int -p(x)lnp(x)dx\] \[\theta \leftarrow \theta +\alpha \nabla_\theta \sum\limits_{i=t-N+1}^t lnp_\theta(a_i\vert s_i)A_i + \lambda H_i(p_\theta(a_i\vert s_i))\]결론적으로 엔트로피를 올리는 것도 고려하면서 학습이 이뤄짐.
엔트로피를 올린다는 것은 policy의 불확실성을 올린다는 의미고 uniform하게 action을 샘플링하는 것을 의미한다고 생각할 수 있음.
이는 액션을 uniform하게 뽑아서 Exploration을 하겠다는 의미이고 마치 Q-Learning의 $\epsilon$-greedy와 동일한 의미로 해석할 수 있음.
Experiments
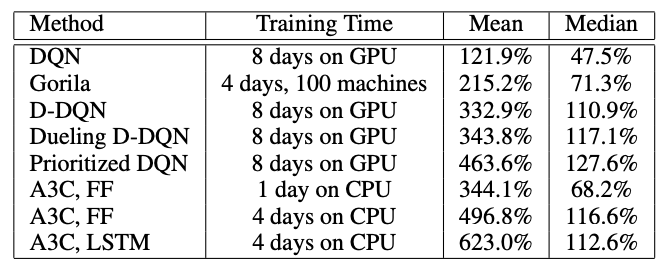
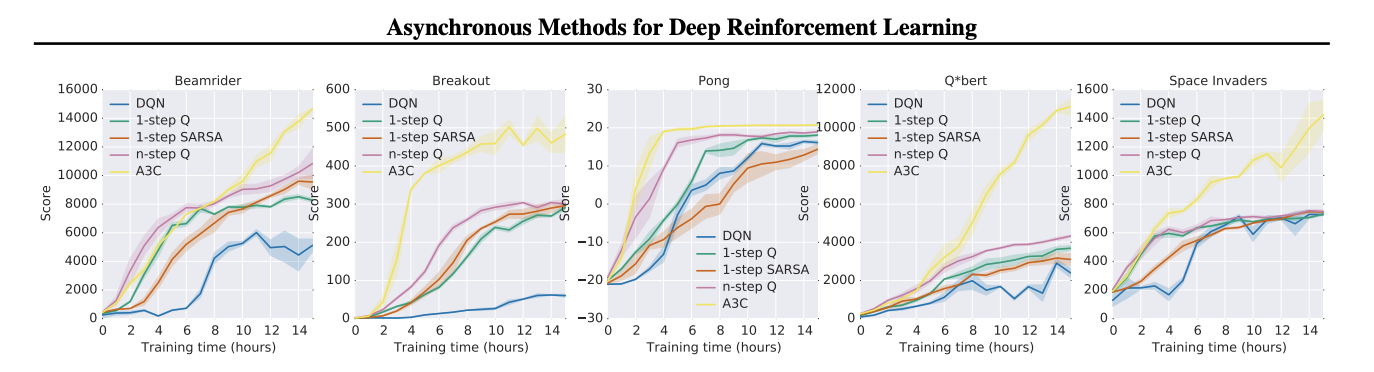
Comments