
Predicting Image Rotation
15 Apr 2020 | self_supervisedUNSUPERVISED REPRESENTATION LEARNING BY PREDICTING IMAGE ROTATIONS
Abstract
최근 몇년간 CNN은 높은 수준의 semantic image features를 배울 수 있는 capacity 덕분에 컴퓨터 비전분야를 변화 시켰습니다.
하지만 CNN을통해 features를 성공적으로 학습하려면 많은 양의 labeled data가 필요합니다.(하지만 labeled data는 비싸고 우리가 원하는 양 만큼 만들기엔 비현실적이죠)
그러므로 Unsupervised semantic feature learning은 오늘날 이용 가능한 방대한 양의 시각 데이터를 성공적으로 사용할 수 있게 하기 위해서 매우 중요합니다.
논문에서 우리는 입력으로 얻는 이미지에 적용되는 2d rotation을 인식하도록 ConvNets를 훈련시켜 image features를 배우도록 제안합니다.
위 작업이 semantic feature를 학습하기 위한 매우 강력한 supervisory signal을 제공한다는 것을 질적으로나 양적으로 보여줍니다.
Introduction
최근 몇년간의 CNN은 많은 양의 manually labeled data를 통해 이미지 understanding task에 적합한 visual representation을 학습할 수 있었습니다.
또한 ConvNet이 supervised 방식으로 학습한 image features는 다른 비전 작업으로 변환할 때 탁월한 결과를 얻었습니다.(such as object detection, semantic segmentation, image captioning)
그러나 Abstract에서 언급했듯 우리는 현대에 들어 방대한 양의 unlabeled image data를 가지고 있으나 supervised task에서는 사용할 수 없습니다.
그로 인해 최근 unsupervised manner로 높은 수준의 ConvNet 기반 representations를 배우려는 관심이 높아지고 있습니다.
그 중에서도 feature learning을 위한 대리 감독 신호를 제공하기 위해 이미지 또는 비디오에 존재하는 visual information만을 사용하여 pretext task를 정의하는 self supervised learning이 인기가 많습니다.
Pretext task란?
네트워크가 어떤 문제를 해결하는 과정에서 영상 내의 semantic한 정보들을 이해할 수 있도록 학습되게 하는 임의의 task
이렇게 pretext task를 통해 얻어진 feature를 다른 task로 transfer 시켜서 사용한다고 합니다.
실제로 위의 SSL(self supervised learning)을 통해 얻은 image representation은 supervised-learned representation과 일치하진 않지만 객체 인식, 객체 감지와 같은 다른 비전 작업으로 transferring하기 위한 좋은 대안임을 이미 여러 논문에서 입증 했습니다.
우리는 SSL패러다임을 따르고, 입력으로 얻는 이미지에 적용되는 기하학적 변환(geometric transformation)을 인식하기 위해 ConvNet을 훈련시켜 image representation을 배우도록 제안합니다.
우리는 기하학적 변환을 정의하고 해당 변환을 데이터에 각각 적용한 뒤 변환된 이미지를 각 이미지의 변환을 인식하도록 훈련된 ConvNet의 모델에 공급합니다.
위 방식에서 ConvNet이 학습해야하는 pretext task를 실제로 정의하는 것은 rotation(기하학적 변환)을 정의하는 부분입니다. 따라서 Unsupervised semantic feature을 학습하려면 이러한 rotation을 올바르게 선택하는 것이 매우 중요합니다.(아래에서 자세히 설명함)
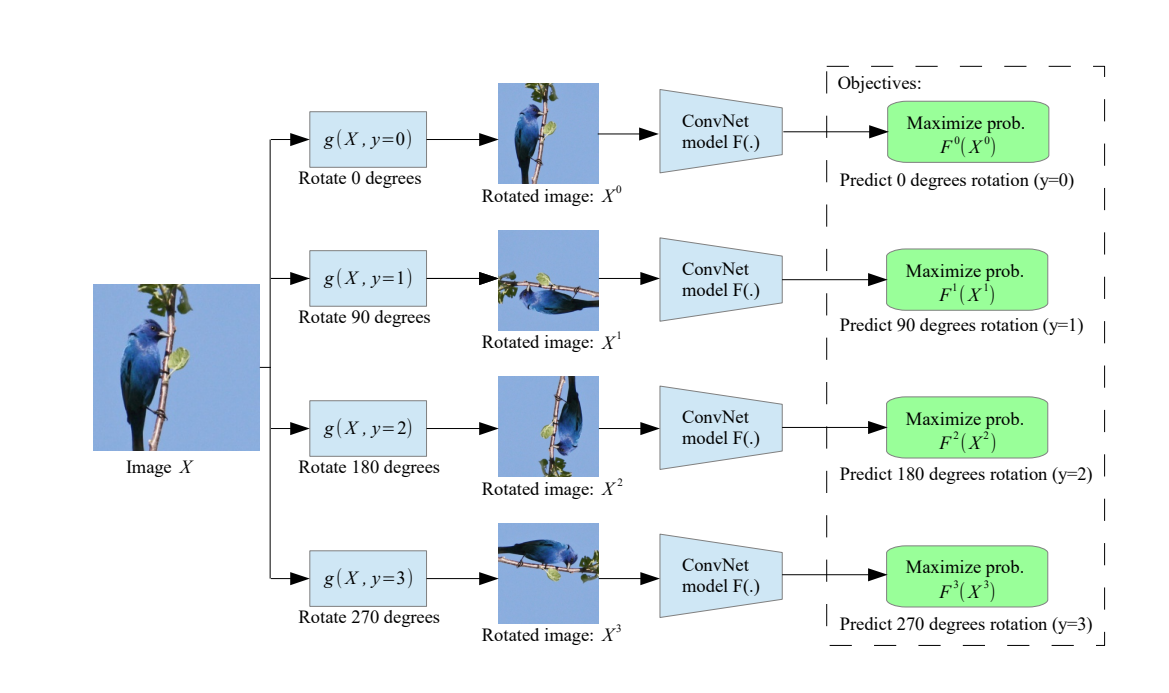
우리가 제안하는 rotation을 [0,90,180,270]도의 이미지 회전으로 기하학적 변환을 정의 하는 것입니다.
따라서 ConvNet 모델은 4 가지 이미지 회전 중 하나를 인식하는 이미지 분류 작업에 대해 학습하게 됩니다.
ConvNet 모델이 이미지에 적용된 회전 변환을 인식할 수 있으려면 이미지에서의 위치와 같은 이미지에 묘사된 객체의 개념을 이해해야 합니다.

Methodology
OVERVIEW
우리의 목표는 Unsupervised manner로 ConvNet 기반의 semantic features를 학습하는 것입니다.
ConvNet : $F(.)$
set of K discrete geometric transformations : $G = {g(.\vert y)}^{K}_{y=1}$
operator that applies to image X the geometric transformation with label y that yields the transformed image $X^y = g(X\vert y)$ : $g(.\vert y)$
$F(.)$ 는 $X^y$를 입력으로 받고, 가능한 모든 geometric transformations에 대한 확률 분포를 출력합니다.
$F(X^{y∗}\vert θ) = {F^y(X^{y∗}\vert θ)}^{K}_{y=1}\tag{1}$
$F(X^{y∗} \vert θ) $는 레이블 y를 사용한 geometric transformations의 예측 확률이고, $θ$는 모델의 파라미터 입니다.
그러므로 N개의 이미지 집합 $D={X_i}^{N}_{i=0}$가 주어질 때 ConvNet모델이 해결하기 위해 배워야하는 SSL의 목표는
$\underset{θ}{min} \frac{1}{N} \sum\limits_{n=1}^{N}loss(X_i,θ)\tag{2}$
이 될것이고, loss fuction은 아래와 같이 정의될 것 입니다.
$loss(X_i,θ) = -\frac{1}{K}\sum\limits_{y=1}^{K}log(F^y(g(X_i\vert y)\vert θ))\tag{3}$
CHOOSING GEOMETRIC TRANSFORMATIONS: IMAGE ROTATIONS
우리는 90도의 배수로 기하학적 변환 집합 G를 정의합니다.(2d image rotations by 0,90,180, and 270)
Forcing the learning of semantic features : 이러한 이미지 회전을 사용하는 핵심적인 이유(직관)는 모델이 객체의 클래스를 인식하고 감지하는 법을 처음으로 배우지 않으면 위의 회전 인식 작업을 효과적으로 수행하는 것이 불가능하다는 단순한 사실과 관련이 있습니다.
모데링 성공적으로 예측을 하기 위해서는 반드시 이미지 내에서 두드러진 객체를 localize하고 방향과 객체 유형을 인식한 다음 사용 가능한 이미지 내에 각 유형의 객체가 묘사되는 지배적인 방향과 객체의 방향을 연관시키는 방법을 배워야 합니다.
레이블 없이 이미지를 줬을 때 그 방향을 예측하려면
적어도 객체가 어디를 보고 있는지 알아야 된다는 뜻이고 그 뜻은 이미지에 대한 어느정도의 이해를 바탕으로 하겠죠?
우리는 (아래에서) 회전 인식 작업에 대해 훈련된 모델에 의해 생성된 attention map을 시각화 합니다.
attention map은 Conv layer의 각 spatial cell에서 activation의 크기에 따라 계산되며 기본적으로 입력 이미지를 분류하기 위해 네트워크가 가장 주의깊게 보는 부분이 차지하는 위치를 반영합니다.
실제로 모델이 회전 예측 작업을 수행하기 위해 이미지에서 눈, 코, 꼬리, 및 머리와 같은 high level object parts에 초점을 맞추는 것을 관측 했습니다.
그림을 보면 supervised와 self-supervised 방식이 거의 비슷한 부분에 초점을 맞추고 있는 것을 볼 수 있습니다.
주목 할만한 점은 이러한 필터는 supervised manner로 학습한 필터 보다 많은 다양성을 갖는 것으로 보입니다.
Absence of low-level visual artifacts: 다른 기하학적 변환에 비해 90도의 배수가 가지는 장점은 low-level visual artifacts를 남기지 않고 flip, transpose로 구현할 수 있다는 점입니다.
반대로 스케일 및 종횡비 이미지 변환과 같은 기하학적 변환은 쉽게 감지 가능한 image artifacts를 남기는 루틴을 사용해야 합니다.
Well-posedness: 사람이 촬영한 이미지는 “up-standing” 위치에 있는 물체를 묘사하는 경향이 있으므로 회전 인식 작업을 잘 정의할 수 있습니다.
up-standing은 똑바로 서 있는 피사체를 생각했습니다.
피사체가 비스듬한 경우 rotation의 인식이 똑바로 있을 때 보다 직관적으로 어려울 것 같습니다.
Implementing image rotations: 이미지 회전을 90, 180, 및 270도 (0도는 기본 이미지)로 구현하기 위해 flip 및 transpose를 사용합니다.

DISCUSSION
Self Supervised task의 간단한 formulation에는 몇 가지 장점이 있습니다.
Supervised manner와 동일한 계산 비용, 유사한 수렴 속도(image reconstruction 방식 보다 훨씬 빠름)
Supervised manner를 위해 고안된 효율적인 병렬화 체계를 사용할 수 있고, 인터넷 규모의 데이터(엄청 많다는 뜻인듯)를 사용할 수 있다는 점입니다.
또한 우리의 접근 방식은 다른 Unsupervised or Self-Supervised와는 달리 trivial features를 배우지 않기 위해 특별한 이미지 사전 처리 루틴이 필요하지 않습니다.
제가 SSL논문을 읽는게 처음이라 “다른 모델들에서 정의하는 pretext task에서는 이미지에서 쓸모없는 features도 배워서 사전처리를 해줘야 하나보다.” 라고 해석했습니다.
Self-Supervised formulation의 단순함에도 불구하고, 논문의 실험 섹션에서 볼 수 있듯 우리의 접근 방식으로 학습한 features는 Unsupervised features learning 벤치 마크에서 크게 개선되었습니다.
Experimental Results


CIFAR EXPERIMENTS
Cifar-10의 객체 인식 과제를 평가하는 것으로 시작합니다.
우리는 SSL방식으로 회전 인식을 훈련한 ConvNet 모델을 RotNet 모델 이라고 부릅니다.
Implementation details: RotNet 모델을 NIN 구조로 구현했습니다.
SGD를 사용했으며 batch size = 128, momentum = 0.9, weight decay = 5e-4, lr = 0.1로 설정 했습니다.
lr은 30, 60, 80 epoch 마다 5배로 감소시키고 총 100 epoch동안 학습합니다.
예비 실험에서 우리는 훈련하는 동안 단일 회전 변환을 무작위로 샘플링 하는 대신 4 개의 회전 된 이미지 사본을 동시에 공급하여 네트워크를 학습 할 때 크게 개선되는 것을 발견 했습니다.
따라서 각 트레이닝 배치에서 네트워크는 배치 크기보다 4배 더 많은 이미지를 봅니다.
Evaluation of the learned feature hierarchies: 먼저 학습 된 features의 품질이 RotNet 모델의 전체 깊이 뿐만 아니라 레이어의 깊이에 따라 어떻게 달라지는지 살펴봅니다.
이를 위해 먼저 cifar-10 이미지를 사용하여 3,4, 및 5개의 컨볼루션 블록이 있는 3개의 RotNet 모델을 학습합니다.(각 블록에는 NIN 구조를 따르므로 3개의 convolution layer가 있습니다.)
그 후에 각 RotNet 모델의 블록에 의해 생성된 feature maps 위에서 classifier를 학습합니다.
classifier는 객체 인식 작업에 대해 Supervised manner로 학습됩니다.
또한 classifier는 완전 연결 층으로 구성되며 2개의 히든 레이어에는 각각 200개의 feature channel이 존재하고, Batch-norm 및 relu가 뒤따릅니다.
위의 표를 보면 알 수 있듯 두 번째 블록(실제로는 NIN 블록이므로 총 6개의 레이어)에 의해 생성된 feature maps가 가장 좋은 정확도를 달성 했습니다.
블록들의 특징은 두 번째를 기점으로 점점 정확도가 감소합니다.
저자는 이것을 SSL로 예측한 작업에 점점 더 구체적이기 시작해서 라고 말합니다.
구체적이라는 뜻이 뭘까요?
크게 CNN을 feature extract와 classifier로 나눴을 때 extract의 끝쪽(거의 맨 마지막CNN layer)은 실제로는 특징을 추출한다기 보다는 Classifier에 영향을 더 줄 것이라고 생각합니다.
그래서 “좀 더 뒤쪽 층으로 갈수록 extract의 기능 보다는 Classifier에 영향을 주는 기능을 많이 학습해서 더 구체적이 된다” 라고 해석했습니다.
또한 RotNet 모델의 전체 깊이를 늘리면 이전 레이어에서 생성된 feature map(첫 번째 블록 이후)에 의해 객체 인식 성능이 향상됩니다.
우리는 이를 모델의 깊이를 늘리면 헤드의 복잡성(최상위 레이어)이 이전 레이어의 feature를 회전 예측에 덜 구체적으로 허용할 수 있기 때문이라고 가정합니다.

(a): 45°의 배수들인 8방향의 회전
(b): 0°, 180°
(c): 90°, 270°
2가지 방향의 경우 인식을 위해 제공하기엔 너무 작은 클래스 이고(less supervised information),
8가지 방향의 경우 기하학적 변환이 충분히 구별되지 않으며 4개의 추가 회전으로 인해 이미지에 시각적 결함이 생길 수 있습니다.
또한 우리는 같은 2가지 방향이지만 (b)가 (c)보다 성능이 좋은 것을 발견했는데,
이것은 아마도 이전 모델이 Unsupervised phase에서 0° 회전을 “보지” 않기 때문입니다.
Exploring the quality of the learned features w.r.t. the number of recognized rotations: 위의 테이블에서는 Self Supervised features의 quality가 각각의 rotation에 얼마나 영향을 받는지를 나타냅니다.
4개의 회전(논문에서 사용한)이 실제로 다른 8, 2개의 경우 보다 더 나은 물체 인식 성능을 달성한다는 것을 관찰했습니다.
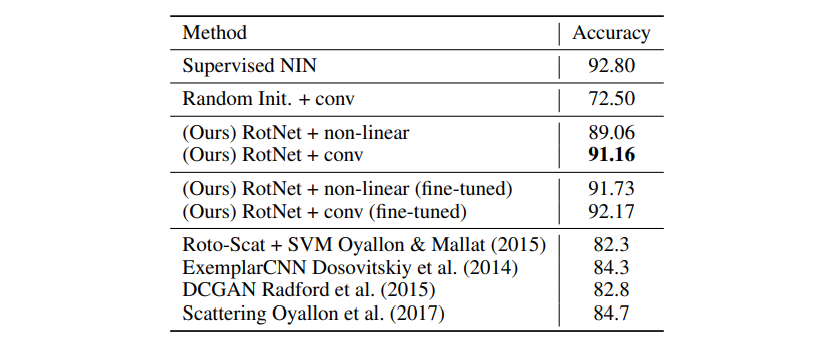
Comparison against supervised and other unsupervised methods: 위 테이블에서는 우리의 Unsupervised learned feature와 다른 Unsupervised(or hand-crafted) features를 비교합니다.
우리는 전체 블록 수가 4인 RotNet 모델의 두 번째 블록에 의해 생성된 feature map을 사용합니다.
위에서 설명했듯 총 블록 수 3, 4, 5(NIN 구조이므로 각 블록은 3개의 convolution layer를 가집니다)가 있는데
앞으로 편의상 RotNet3, RotNet4 등으로 표기하겠습니다.
또한 두 가지 Classifier를 학습합니다.
(a): 이전과 같이 3개의 완전 연결 층이 있는 non-linear Classifier((Ours) RotNet + non-linear)
(b): 3개의 convolution layer + linear prediction layer((Ours) RotNet + conv)
(b)는 기본적으로 3 블록 NIN 모델이며, 처음 2 블록은 RotNet 모델에서 오고
3rd 는 무작위로 초기화 되어 인식 작업에 대해 훈련됩니다.
우리는 이전의 Unsupervised approches를 개선하고 CIFAR-10에서 SOTA를 달성했습니다.
특히 RotNet 기반 모델과 Supervised NIN 모델 간의 정확도 차이는 매우 작습니다.(약 1.64%)
Unsupervised learned features를 fine-tuning하면 분류 성능이 더욱 향상되어 Supervised case와의 격차가 훨씬 줄어듭니다.
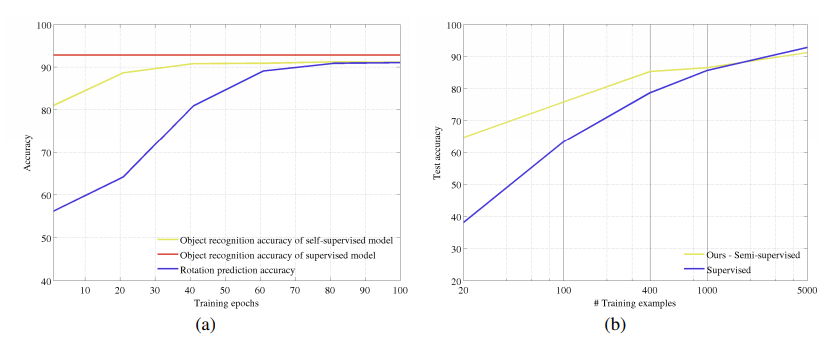
Correlation between object classification task and rotation prediction task: 위 그래프 (a)는 회전을 인식하는 Self-Supervised task를 해결하는데 사용되는 Training epoch의 함수로 객체 분류 정확도를 플로팅합니다.
구체적으로 물체 인식 정확도 곡선을 생성하기 위해 RotNet 각 훈련 스냅샷(20epoch 까지)에서 훈련 절차를 일시 중지하고 지금까지 배운 RotNet features위에 non-linear object classifier를 맨 처음 부터 수렴할 때 까지 훈련합니다.
따라서 물체 인식 정확도 곡선은 훈련이 끝난 후 non-linear object classifier의 정확도를 나타내며 회전 예측 정확도 곡선은 스냅 샷에서 RotNet의 정확도를 나타냅니다.
회전 예측 작업을 해결하기 위한 RotNet feature가 향상됨에 따라(즉, 회전 예측도가 증가함에 따라) 객체 인식 작업을 해결하는 데 도움이 되는 기능도 향상됩니다.(객체 인식 정확도도 향상됨.)
Semi-supervised setting: 우리의 Unsupervised feature learning method의 높은 성능에 영감을 받아서 semi-supervised 환경에서도 평가합니다.
먼저 CIFAR-10의 전체 이미지 데이터를 사용하여 회전 예측 작업에 대해 RotNet4 모델을 학습한 다음 사용 가능한 이미지 서브셋과 해당 레이블만 사용하여 feature map 객체 분류기 위에서 학습합니다.
우리는 RotNet모델의 두 번째 블록에 의해 생성된 feature map을 사용합니다.
객체 분류기를 훈련 시키기 위해 우리는 각 카테고리 별로 20,100,400, 1000 또는 5000 이미지를 사용합니다.
카테고리별 5000개의 이미지면 실제로는 cifar-10의 전체 데이터를 말합니다.
class수가 10개고 전체 데이터가 5만장으로 알고 있습니다.
또한 매번 사용 가능한 예제에 대해서만 학습된 Supervised model과 방법을 비교합니다.
우리는 사용 가능한 훈련 예제의 함수로 검사된 모델의 정확도를 플로팅합니다.
카데고리당 예제 수가 1000개 미만으로 떨어질 때 Unsupervised trained model이 semi-supervised setting에서 Supervised model의 성능을 초과합니다.
예제 수가 줄어들수록 이 방법에 대한 성능 차이가 증가합니다.
이 실험적 증거는 semi-supervised setting에 대한 방법의 유용성을 보여줍니다.
Conclusions
우리는 입력 이미지에 적용된 이미지 회전을 인식할 수 있도록 ConvNet 모델을 훈련 시키는 Self Supervised feature leaning 학습을 위한 새로운 formulation을 제안합니다.
SSL task의 심플함에도 불구하고, 우리 모델은 객체 인식, 객체 감지 및 객체 분할과 같은 다양한 시각적 인식 작업에 유용한 semantic feature를 배울 수 있다.
Comments