
GoogLeNet
22 Mar 2020 | visionGoing Deeper with Convolutions
Implementation
Network In Network
GoogLeNet의 참조 논문입니다.
NIN은 말그대로 network 안에 network를 집어 넣는 구조를 뜻합니다.
일반적인 CNN의 필터는 linear한 특징을 가집니다. 이로 인해 feature extract(논문에선 Data abstract라고 표현합니다.)도 linear한 부분에는 잘 적용되지만 non-linear feature에 대해서는 잘 찾지 못한다 라는 점에서 출발합니다.
이 부분을 극복하기 위해 feature-map의 개수를 늘려야 하는 문제에 주목했지만 필터의 개수를 늘리게 되면 연산량이 늘어나는 문제가 있습니다.
이를 해결하기 위해 NIN은 more complex Architecture로 receptive filed에서 data abstract를 시도합니다.
위에서 더 복잡한 구조를 위해 micro neural network를 설계 하였고 필터 대신에 MLP(Multi-Layer Perceptron)을 사용합니다.
사실 Perceptron에 activation이 포함되어있기 때문에 직관적으로 생각해도 MLP를 추가하면 당연히 non-linearity가 증가할 것 같습니다.
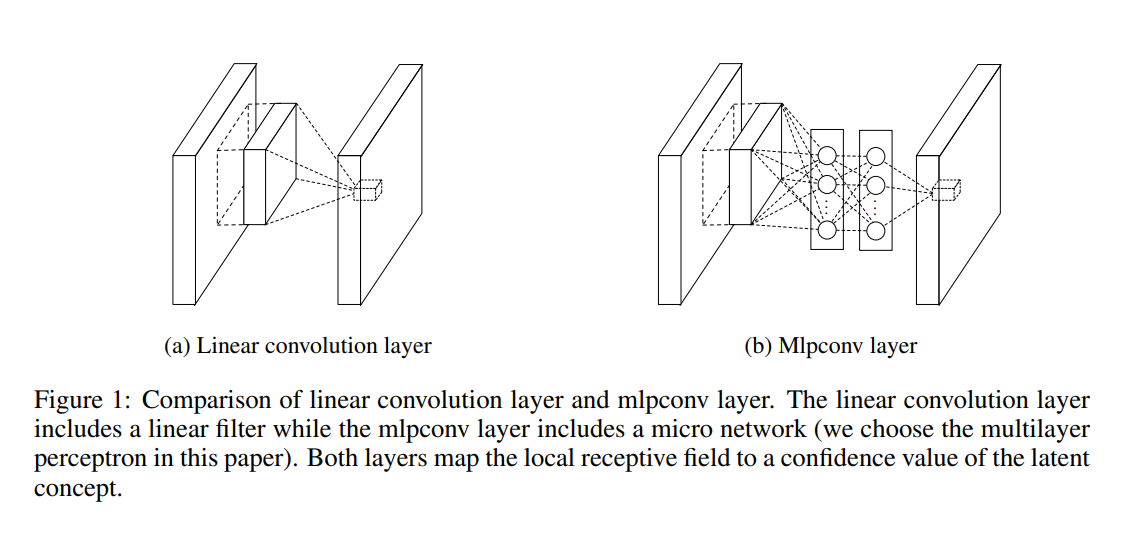
필터의 linear연산은 그대로 수행하며 activation을 포함하기 때문에 non-linear한 성질을 잘 활용할 수 있습니다.
또한 1x1 conv를 사용하여 feature map의 채널 수를 줄여서 파라미터 개수를 전체적으로 감소시킬 수 있습니다.
최종적으로는 Global Average Pooling을 사용하여 Fully connected layer을 없앴는데, 앞에서 효과적으로 feature vector를 추출했기 때문에 추출된 vector에 대해 pooling하는 것으로 충분하다고 주장합니다.
위의 GAP또한 FC에 비해 연산량이 적기 때문에 굉장한 이점을 가집니다.
Abstract
ILSVRC14에서 최고 성능을 보인 Inception이라 불리는 새로운 아키텍쳐를 제안합니다.
이 아키텍쳐의 특징은 네트워크 안에서 컴퓨팅 리소스의 활용을 향상시켰습니다.
리소스를 일정하게 유지하면서 네트워크의 깊이와 너비를 증가할 수 있도록 설계해서 가능했습니다.
ILSVRC14에 제출된 모델은 22layers deep 네트워크인 GoogLeNet이라고 하며 분류 및 탐지 부분에서 평가되었습니다.
Introduction
지난 몇년간 딥러닝의 발전과 구체적으론 CNN의 발전으로 이미지 인식과 객체인식은 엄청난 속도로 발전해왔습니다.
좋은 소식은 단순히 하드웨어의 향상으로 인한 기술 발전이 아닌 새로운 아이디어와 알고리즘 및 향상된 네트워크 아키텍처의 결과라는 점입니다.
대부분의 실험에서 모델은 1.5억번의 연산을 넘지 않도록 설계했으며, 이는 단순히 학술적 호기심으로 끝나는게 아닌 실제로 사용하기 위함입니다.
논문에서 “deep”이라는 단어는 두가지를 의미합니다.
- “Inception module”의 형태로 새로운 수준의 조직을 도입한다는 의미
- 네트워크의 depth를 늘린다는 의미
Inception model은 Arora의 이론적 연구에서 영감과 지침을 얻으며, Network in Network 모델의 논리적인 절정으로 볼 수 있습니다.
Related Work
LeNet-5를 시작으로 CNN은 Convolution stack(Conv-maxpool)과 FCN이 뒤따르는 일반적인 구조를 가집니다.
ImageNet과 같은 큰 데이터 셋을 사용하는 경우 최근 추세는 오버 피팅 문제를 해결하기 위해 Dropout을 사용하는 동안 레이어 수 및 레이어 크기를 늘리는 것이었습니다.
Maxpooling이 정확한 공간 정보의 손실을 초래한다는 우려에도 불구하고 다양한 image task에서 성공적으로 사용되었습니다.
영장류 시각 피질 신경과학 모델에서 영감을 받은 “robust object recognition with cortex-like mechanisms” 에서는 여러 스케일을 처리하기 위해 크기가 다른 일련의 고정 Gabor filter를 사용했습니다.
우리도 비슷한 전략을 쓸겁니다.
그러나 위 논문의 고정된 2-layer 모델과는 달리 Inception 아키텍쳐의 모든 필터가 학습됩니다.
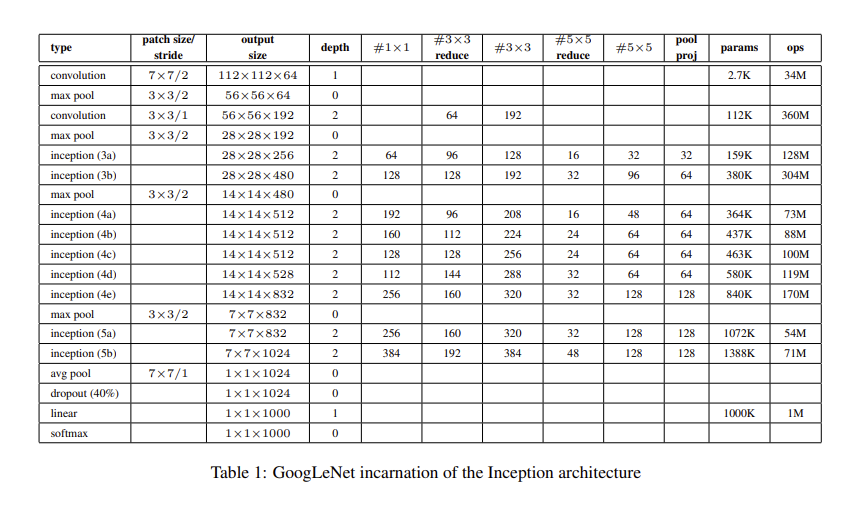
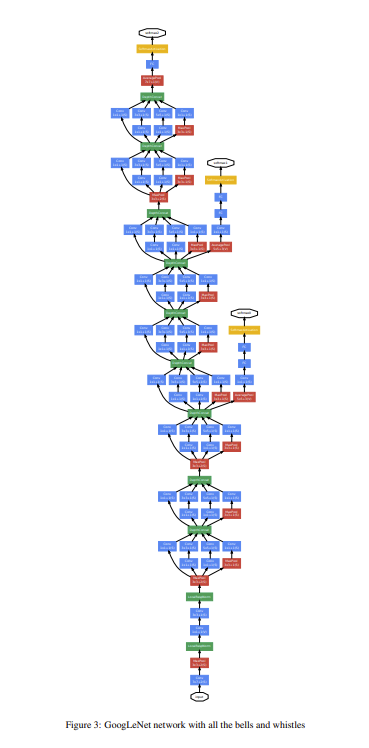
또한 Inception Layer는 여러번 반복되어 GoogLeNet 모델의 경우 22-layer까지 이어집니다.
NIN에서 사용하는 1x1conv(채널 방향의 pooling)과 ReLU가 뒤따르는 방식이 우리의 아키텍쳐에서도 많이 사용됩니다.
우리 아키텍쳐에서 1x1conv는 두 가지 목적을 가집니다.
중요한 것은 주로 컴퓨터 병목현상을 제거하기위해 차원 축소 모듈로 사용되며, 그렇지 않을 경우 네트워크의 크기를 제한합니다.
이를 통해 성능을 크게 저하시키지 않으면서 네트워크의 깊이와 높이를 증가시킬 수 있습니다.
마지막으로 객체 인식을 위한 SOTA 모델인 RCNN에서 전체 인식 문제를 두가지 하위 문제로 분리하는 방법도 이용합니다.
- region proposals
- using CNN classifiers
우리는 객체 인식을 위해서 유사한 pipeline을 채택했지만 더 좋은 개선점을 찾았습니다.
Motivation and High Level Considerations
DNN 성능 향상의 가장 단순한 방법은 사이즈를 늘리는 것입니다.
사이즈를 늘리는 것은 depth와 width 두 가지를 포함합니다.
위 방법은 대량의 학습용 데이터가 있을 때 높은 성능의 모델을 쉽고 한전하게 교육하는 방법입니다.
하지만 이 간단한 솔루션에도 두 가지 결점이 있는데,
더 큰 사이즈는 일반적으로 많은 수의 파라미터를 뜻하고, 훈련 세트에서 데이터가 제한된 경우 더 커진 네트워크에서 오버피팅이 일어나기 쉽습니다.
특히 fig.1에서 알 수 있듯이, ImageNet과 같이 세밀한 범주를 구분해야 하는 경우 고품질의 학습 데이터를 만드는 것은 심각한 병목현상이 될 수 있습니다.
또 다른 단점은 네트워크 크기의 증가가 엄청난 컴퓨팅 리소스의 사용을 증가시킵니다.
또한 추가된 capacity가 비효율적으로 사용된다면(대부분의 가중치가 0에 가까워 질 경우) 많은 자원이 낭비됩니다.
이 두가지 문제를 해결하는 기본적인 방법은 sparsity를 도입하고, fully connected layer를 sparse ones로 대체하는 것입니다.
생물학적 시스템을 흉내내는 것 외에도, Arora로 인해 확고한 이론적 토대를 가질 수 있었습니다.
Their main result states that if the probability distribution of the dataset is representable by a large, very sparse deep neural network, then the optimal network topology can be constructed layer after layer by analyzing the correlation statistics of the preceding layer activations and clustering neurons with highly correlated outputs.
Architectual Details
The main idea of the Inception architecture is based on finding out how an optimal local sparse structure in a convolutional vision network can be approximated and covered by readily available dense components.
이 문장이 핵심이라고 생각합니다.
Optimal local sparse structure를 찾되, “어떻게 하면 우리가 가진 dense component로 잘 approximate해서 사용할 수 있을까?
데이터 셋의 확률 분포가 존재할 때 아주 큰 sparse DNN으로 표현할 수 있다면, 그 문제를 풀 수 있는 optimal network topology는 layer by layer로 correlation statistics를 분석하여 구조를 짜면 polynomial time 안에 문제를 풀 수 있다.(Arora)
(! 내 생각 : 아무래도 크기를 늘려서 sparse한 구조로 만들면 성능과 반비례하게 Overfitting or 연산량의 증가가 발생하기 때문에 성능을 sparse structure로 잡고, 연산량을 dense component로 잡는다는 얘기일 것 같다.)
어떤 노드들을 지난 output이 상관관계가 높으면 그 노드들을 클러스터링 해줍니다.(Hebbian principle)
가장 중요한건 Sparse와 Dense간의 중간 지점을 찾는 것인데,
Sparse는 성능이 좋고, Dense는 연산이 빠릅니다.
우리는 이미지에서 correlation을 생각해봅시다. 대충 비슷한 color, texture등등 이 떠오르는데 이런 Local들을 conv로 표현하면 1x1로도 가능할 것입니다.
좀 더 퍼진 범위의 correlation은 3x3, 마찬가지로 5x5로 더 넓은 범위의 correlation을 계산할 수 있습니다.
(또한 굳이 1x1, 3x3, 5x5로 구성한 이유는 편리함을 위한 결정이라고 언급합니다.)
위의 레이어들을 결합하면 바로 naive한 Inception Module이 됩니다.(물론 이건 잘 동작안함)
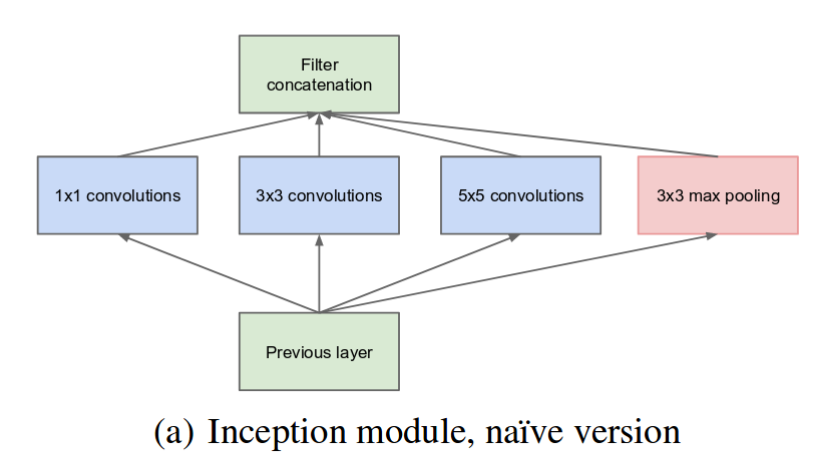
당시에 Maxpool이 일단 넣으면 잘돼서 넣은걸로 알고 있습니다.
물론 저대로는 사용하지 못합니다 애초에 abstract에서도 컴퓨팅리소스에 대해 그렇게 강조했는데 저러면 연산량이 너무 많아서 배보다 배꼽이 크게 됩니다.
여기에다가 NIN에서 영감을 얻은 1x1 Conv를 사용해서 문제를 해결합니다.
1x1 Conv에는 두 가지 목적이 있습니다.
- 1x1 Conv를 사용하면 채널수 줄이기가 가능하니까 connection이 줄고, 이로 인해 연산량이 줄어듭니다.
- ReLU를 포함하여 non-linearity를 늘릴 수 있다.
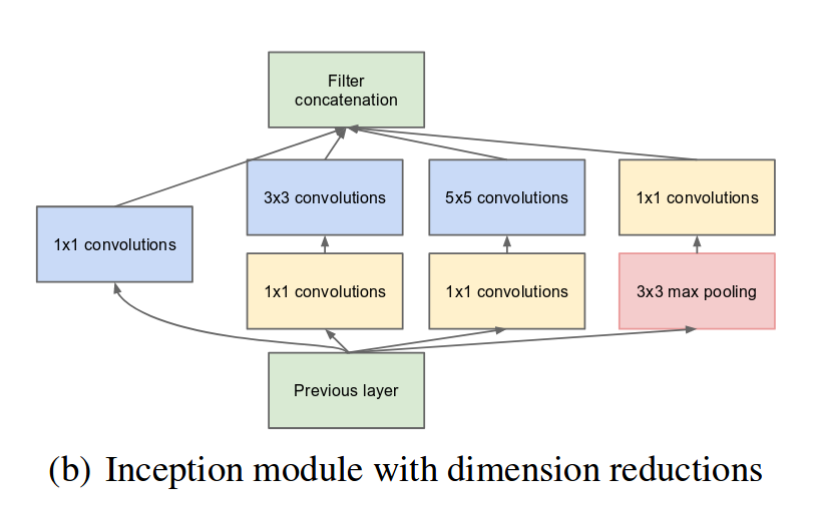
사실 무작정 채널 수를 줄이게 되면 representation 할 수 있는 capacity가 줄어들지만 초기나 이후의 레이어에서도 네트워크 필터들이 상당히 유사한 점들이 많아서(highly correlated) dimension reduction을 수행해도 별 문제 없이 data representation이 가능합니다.
Comments