
Dropout
29 Jan 2020 | techDropout: A Simple Way to Prevent Neural Networks from Overfitting
드롭 아웃은 굉장히 유명한 오버피팅을 막는 방법 중에 하나입니다.
굉장히 간단한 방법으로 오버피팅을 상당히 없앨 수 있고 다른 정규화 방법들 보다 많은 성능 개선을 이룰 수 있습니다.
Introduction
간단히 어떻게 동작하는지 알아보고 갑시다.
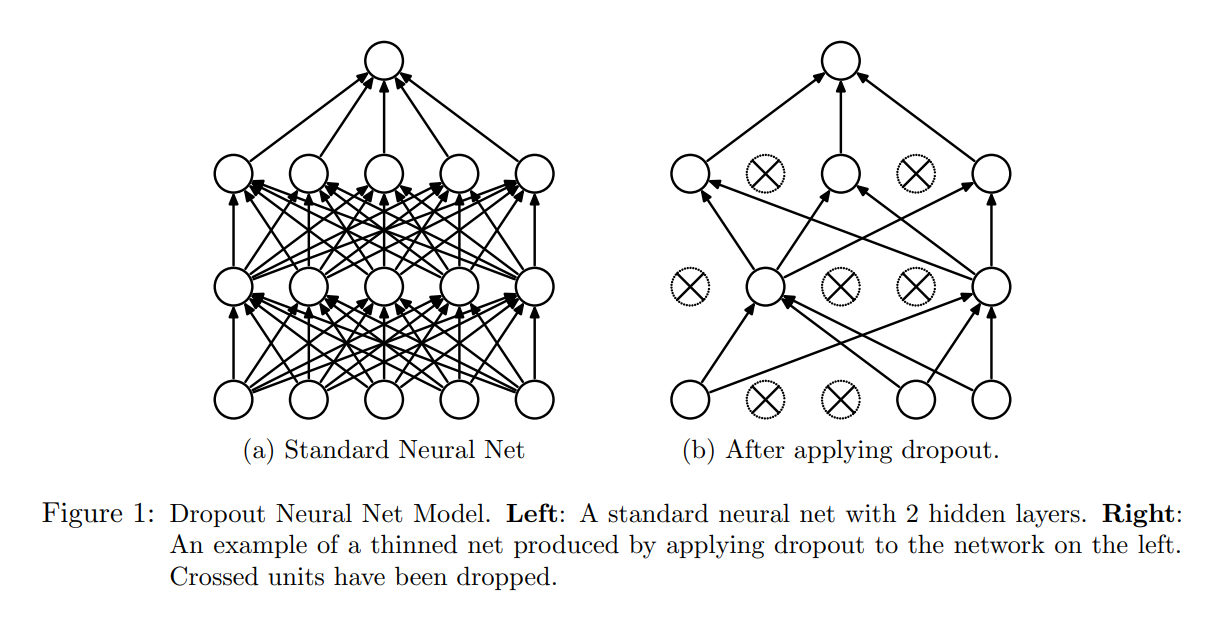
원리는 간단합니다. 학습 중에 무작위로 뉴런을 ‘Drop’ 시킵니다.
이렇게 되면 오버피팅도 해결하고 성능도 올라간다니 살짝 마술같지 않나요?
왜 저런 단순한 기믹이 모델의 성능을 높일 수 있는지 알아봅시다.
Overfitting
드롭아웃의 효과를 설명하려면 오버피팅에 대한 얘기를 해야합니다.
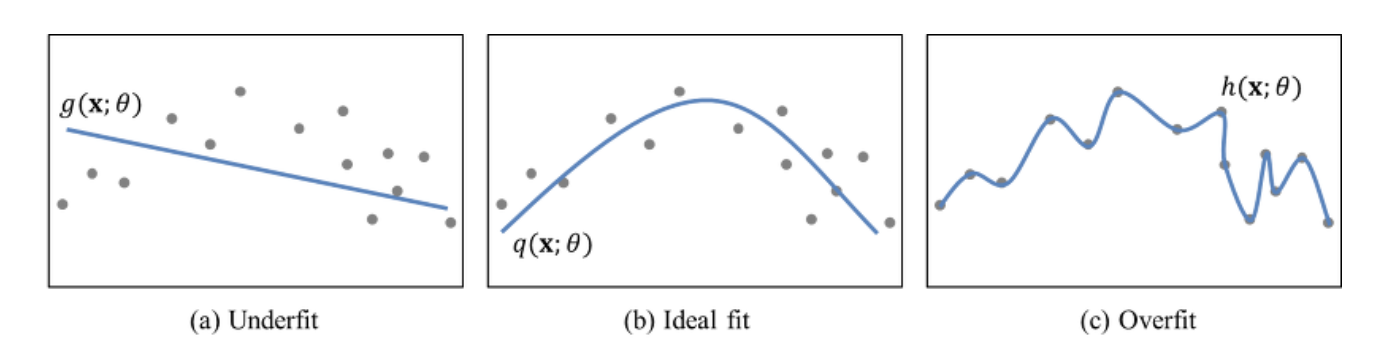
딥러닝은 선천적으로 high variance입니다. 이 얘기는 (c)처럼 데이터에 따라 모델이 심하게 맞춰지려 한다는 뜻입니다.
Bias-Variance Trade-off라는 말이 있습니다. MSE를 사용한 regression 문제를 떠올려 봅시다.
\[gt = f(x)+\epsilon\]여기서 $\epsilon$은 noise입니다.
우리가 궁극적으로 최적화 하려는 loss의 기댓값 $E[(gt-y)^2]$ 은 다음과 같이 bias, variance, noise로 분해 가능합니다.
\[E[(gt-y)^2] = E[(gt-E[y])^2] + E[(E[y]-y)^2] + E[\epsilon^2]\]noise는 모델과 독립이라 최소화 하는 것이 불가능합니다. 결국 loss의 기대값을 최소화하려면 bias와 variance를 최소화 해야 합니다.
위 식을 보면 알겠지만 한쪽을 최소화하면 다른쪽이 커지는 관계입니다. 딥러닝은 var loss, bias loss 둘 다를 고려해서 최적의 해를 찾는 것입니다.
오버피팅이라 하는 것은 train set에 대해서는 저 두 가지 로스가 낮은데(최적점) 새로운 test set에 대해서는 var loss가 다시 커진 것으로 해석할 수 있습니다.
오버피팅이 뭔지 알겠습니다. 그래서 어떻게 해결할 수 있을까요? 위 그림을 보면 bias를 조금 높이면 variance를 줄일 수 있을 것 같습니다. 그렇다면 뉴런들에 bias를 추가해봅시다.
학습 중인 네트워크의 뉴런에 노이즈를 추가하는 것은 bias를 추가하는 것으로 볼 수 있습니다. 여기서 중요한 점은 bias가 지나치면 안된다는 것입니다. 일반적인 정규분포에서 샘플링한 노이즈를 추가해봅시다.
$x’= x+\epsilon$ 이렇게 해도 $E[x’] = x$로 기대값은 변하진 않습니다. 하지만 중간 층에서 이 노이즈의 스케일이 적절하지 않을 수도 있습니다. 대안은 확률 변수를 이용하는 것입니다.
뉴런이 ‘Drop’될 확률을 $p$로 설정해봅시다.(논문에선 반대로 ‘retained’ 될 확률을 p로 설정합니다.)
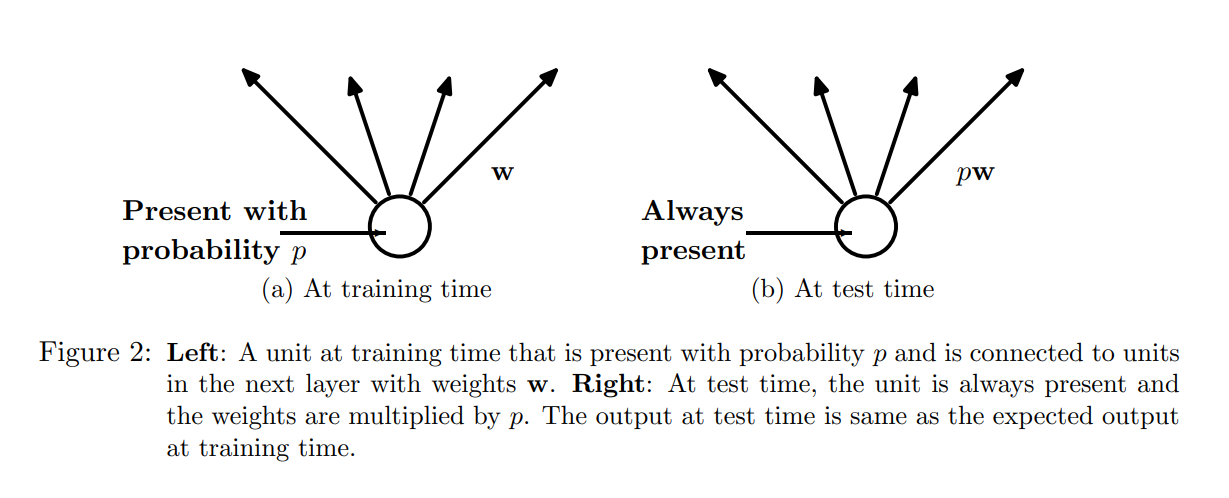
이처럼 확률 변수로 뉴런들을 표현할 수 있습니다. 확률이 $p$인 경우 0을 출력합니다. 이렇게 설계하면 기댓값이 변하지 않습니다. $E[h’] = h$ 중간 레이어에 적용되는 활성화 $h$에 대하여 같은 기대값을 갖는 확률 변수 $h’$로 바꾸는 것이 드롭 아웃의 핵심입니다.
한 가지 주의해야 할 점은 테스트 시에는 드롭 아웃을 사용하지 않고 유닛에 연결된 가중치에 $p$를 곱해줘야 합니다.
Effect
뉴런들을 확률 변수로 바꿔주면 어떤 효과가 생길까요?
결과적으로 우리의 목적은 오버피팅을 막는 것이므로 딥러닝의 여러 오버피팅을 막는 기법들과 효과는 비슷합니다 결국 축소시키고 규제하는거죠.
1. Ensemble
모델은 매번 새로운 뉴런 구조를 가지게 됩니다. 이는 곧 여러 모델을 학습하는 것과 동일한 효과를 가지게 됩니다. 즉, 드롭 아웃을 통해 어느정도 앙상블 효과를 기대할 수 있습니다.
2. Co-adaption
특정 뉴런이 크게 활성화 되면 상대적으로 다른 뉴런들은 학습이 느려지게 됩니다. 드롭 아웃을 통해 특정 뉴런의 가중치나 바이어스가 지배적인 역할을 하는 것을 규제할 수 있습니다. 이를 통해 오버피팅을 막고 일반화 성능을 기대할 수 있습니다.

3. Optimization
드롭 아웃과 다른 정규화를 동시에 사용하면 더 좋은 성능을 얻을 수 있습니다.
드롭 아웃으로 인한 Noise + 규제를 통한 높은 learning rate를 통해 error space에서 더 넓은 공간을 탐색하여 최적의 해를 찾을 수 있습니다.

4. Sparsity
드롭 아웃의 부가적인 효과는 히든 유닛의 activation 값이 sparse해집니다. 심지어는 sparse해지지 않도록 정규화를 거쳐도 sparse해집니다.
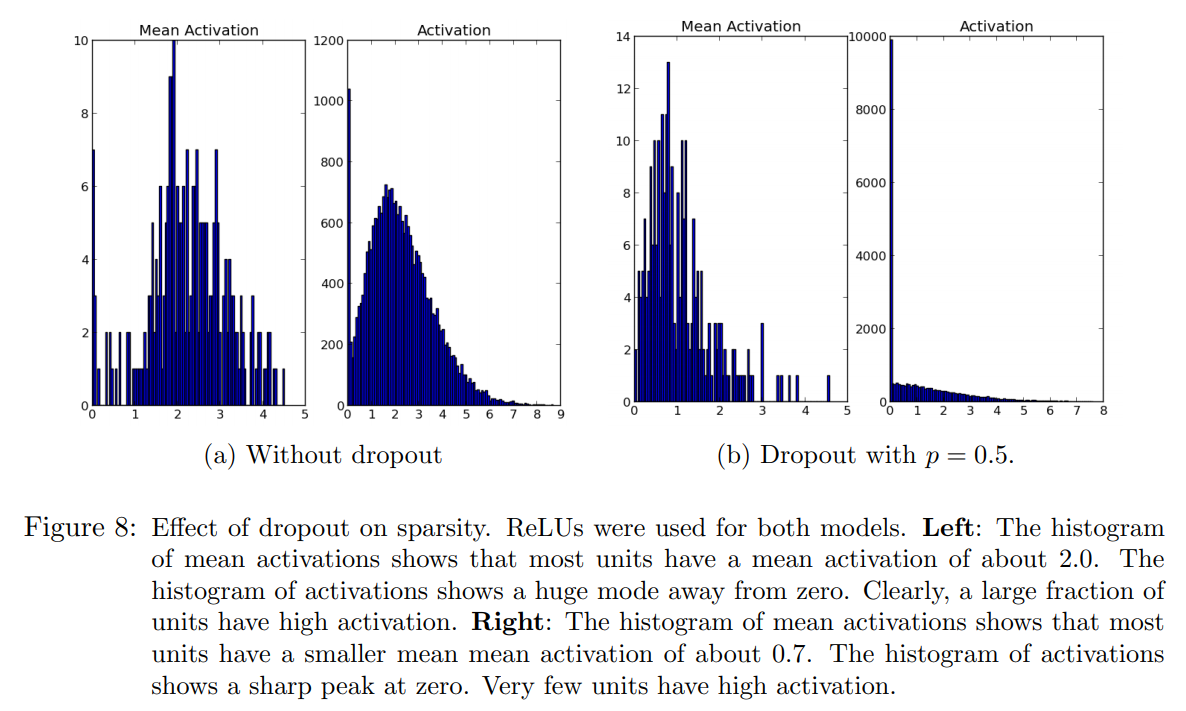
Conclusion
궁극적으로 하고싶은 말은 오버피팅을 피하려면 데이터를 많이 모으거나, 아니면 모델에 어떤식으로든 규제를 추가해야 된다는 점입니다.
그게 bias를 추가하든, weight decay처럼 튀는 값을 애초에 제한하든, 차원 축소처럼 필요한 정보만 남기고 없애 버리든, 드롭 아웃처럼 파라미터를 줄이든 어떻게든 규제를 하기위해 애써야 오버피팅을 피할 수 있는 것 같습니다.
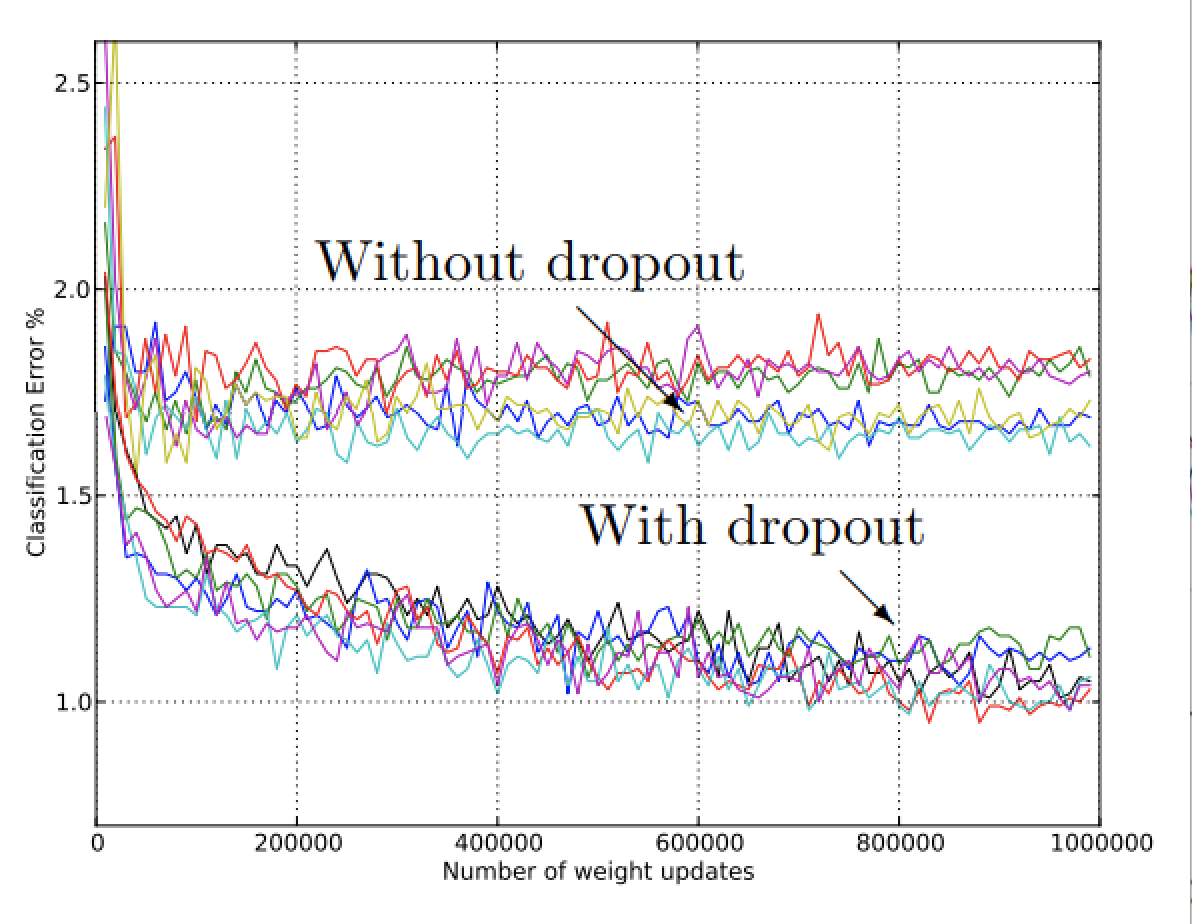
P.S 오버피팅이 모델 복잡도랑 관련이 있는데 사실 딥러닝의 복잡도 하면 제일 먼저 떠올랐던건 activation function입니다. 애초에 이게 없으면 linear해지니까요 이 부분을 건드려도 오버피팅을 막을 수 있진 않을까? 생각해봤습니다. 물론 그냥 빼버리면 애초에 쌓는 이유가 없으니까.. 어떤 기믹이 있긴 있어야 겠죠..?
Comments