
AlexNet
26 Jan 2020 | visionAlexNet : ImageNet Classification with Deep Convolutional Neural Networks
AlexNet은 2012년 개최된 ILSVRC대회 우승을 차지한 모델입니다. 이 대회 우승을 통해 딥러닝이 대중들에게 주목을 받기 시작합니다.
이 논문의 저자가 Alex Khrizevsky라서 모델 이름이 AlexNet입니다.
그나마 선행 지식 없이도 읽을 수 있는 원조격 논문인 것 같습니다. (굳이 필요하다면 CNN이나 Lenet-5?) 여기서 나온 테크닉이 아직까지 쓰이는 것들이 많습니다. (Parallel GPU, ReLU, Drop out)
Architecture
우선 구조를 살펴봅시다. 기본적으론 Lenet-5와 크게 다른점이 없습니다.
AlexNet은 2개의 GPU를 사용하는 병렬 구조입니다.
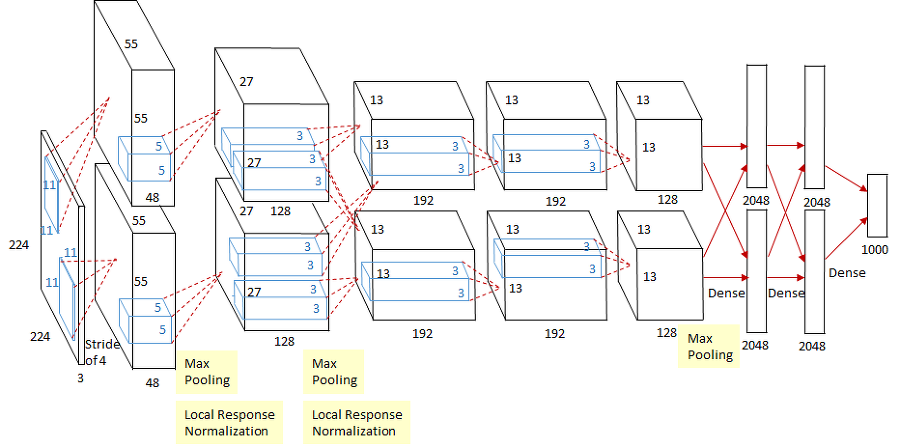
AlexNet은 5개의 convolution layer, 3개의 fully connected layer로 구성됩니다.
재밌는 사실은 각 GPU별로 다른 feature를 추출한다는 점입니다.
첫 번째 GPU로는 컬러와 상관 없는 정보를 추출하고, 두 번째 GPU로는 컬러와 관련된 정보를 추출한다고 합니다.
위 그림에서 볼 수 있듯 세 번째 레이어 부터는 두 가지 GPU의 결과를 섞어서 사용합니다.
여기서 문득 든 생각은 사실 AlexNet의 저자는 GPU memory의 제한때문에 병렬적인 구조를 택했을 것이다.
그러나 어떻게 보면 feature decouple로도 볼 수 있을 것 같다. 비교적 최근에 읽은 Xception에서 하려는 task도 Channel-Correlation과 Spatial-Correlation을 분리시키려고 노력했는데 AlexNet도 저런 부분에서 얻어가는 것은 없었을까? 라는 생각이 든다.
인풋 사이즈가 224x224x3으로 꽤 크기 때문에 첫 번째 레이어에서 11x11x3이라는 큰 receptive field를 사용하고 전체적으로 파라미터의 수가 굉장히 많은 것을 볼 수 있습니다.
마지막 레이어에선 Softmax를 사용하여 ImageNet 분류를 위해 1000개의 클래스에 대한 확률 값을 뽑아냅니다.
ReLU
사실 ReLU는 AlexNet에서 최초로 사용한건 아닙니다. 하지만 이전의 non-linear layer는 대부분 tanh를 사용했다고 합니다.
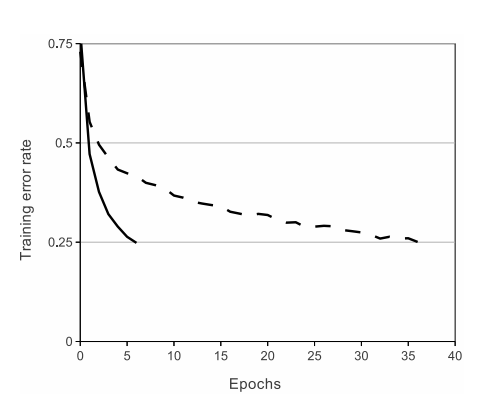
tanh는 sigmoid보단 낫지만 여전히 학습 속도가 느립니다. AlexNet은 ReLU를 사용했을 때 sigmoid나 tanh를 사용했을 때 보다 학습 속도가 6배 빨라지는 것을 볼 수 있습니다.
아래 그래프에서 solid는 ReLU, dashed는 tanh입니다.
Dropout
AlexNet은 당시 기준으로 굉장히 큰 모델이었기 때문에 성능 개선을 위한 앙상블을 고려할 수 없는 모델이었습니다.
마침 당시엔 Dropout이라는 앙상블과 비슷한 효과를 내도록, 모델을 sparsity하게 만들어 주는 기법이 존재했고 이 방법을 사용합니다.
Dropout을 사용하지 않았을 때 모델이 부분적으로 오버피팅 되는것을 확인할 수 있었습니다.
Data Augmentation
딥러닝은 늘 오버피팅과 싸워야 합니다. 오버피팅에 대응하는 가장 좋은 방법 중 하나는 데이터를 많이 모으는 것입니다.
- 256x256이미지를 random crop하여 224x224이미지를 얻고, 이미지를 flip한 상태에서도 crop하여 2048배 늘렸습니다.
- RGB 채널 값을 변화시킵니다. 픽셀 값에 대한 PCA를 수행하고, mean=0, var=0.1의 확률 변수를 곱하고 원래 픽셀 값에 더해줍니다.
Other techniques
앞서 설명한 방법들은 아직까지도 사용되는 대중적이고 유용한 방법들입니다.
AlexNet에서 사용했던 다른 테크닉에 대해 알아봅시다.
1. Overlapped Pooling
사실 Pooling layer가 feature extract에서 꼭 필요한지는 아직 저도 명확히 대답하지 못하겠습니다.
일반적인 지식으론 Max Pooling을 사용하면 이미지의 sharpest feature를 추출할 수 있고, 그것을 통해 low-level representation을 가능하게 한다고 하지만, 제 주관적인 생각으론 단순히 파라미터 수를 줄이고 거기서 최선의 feature를 남기려는 trade-off관계에서 발생한 레이어가 아닐까 생각합니다.
여기서 하고싶은 말은 어떤 생물이나 신경학적 백그라운드에서 일어나는 상호작용을 모방해서 가장 큰 feature를 남긴다 이런게 아니라 단순히 실험적 결과..?에 의해 발생한게 아닐까 생각해봤다.
다른 참고자료에서 Max Pooling이 최대 크기를 갖는 자극만 전달하는게 생물학적 특성과 유사하다는 걸 보고 든 생각임.
성능을 좋게하려면 Pooling을 아예 하지 않거나 Pooling layer조차도 learnable parameter로 구성해서 유용한 정보만 남기면 될텐데.. 사실 이러면 conv-conv-conv의 fully convolutional layer가 되버리는 것 같다.
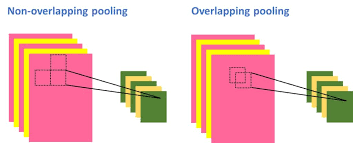
서론이 길었는데 AlexNet에선 MaxPooling을 하지만 대부분의 모델에서 처럼 겹치는 부분 없이 풀링 하는 것이 아니라 겹쳐서 풀링을 수행합니다.
2. Local Response Normalization
Lateral inhibition 이라는 현상이 있습니다.

위의 그림은 mach band라고 불리는데요 (음속을 측정하신 그분 맞습니다.)
색이 변할수록 색 사이에 경계선에서 색이 더 진하게 보이거나 밝게 보이는 효과가 있습니다. 이 효과가 바로 Lateral inhibition입니다.
다른 예시로는 헤르만 격자라는 것이 있습니다.

검은 부분을 보고 강력하게 반응한 뉴런이 흰색으로 둘러싸인 측면에서 억제를 발생시키기 때문에 흰색이 더 반감되어 보인다고 합니다.
전문적으로 말하면 강하게 흥분한 신경세포는 이웃 세포들에게 억제성 신경 전달 물질을 전달하여 이웃 세포들이 덜 활성화 되도록 만든다고 합니다.
이걸 뉴럴네트워크에 적용한 것이 Local Response Normalization입니다.
만약 엄청 강력한 feature가 입력으로 들어온다면 그 feature에 맞게끔 node들이 학습하게 될 것이고(다른 노드들은 억제)이는 오버피팅과 연결될 수 있습니다.
그렇다면 이를 없애려면 어떻게 해야 할까요?
강력한 feature가 나타나는 부분에서 여러 채널의 필터를 sqaure-sum하여 특정 강력한 피처가 나타나는 필터에서의 과도한 activation을 막을 수 있습니다.
\[b^i_{x,y} = a^i_{x,y} / (k+\alpha \sum\limits_{j=max(0,i-n/2)}^{min(N-1,i+n/2)} (a^j_{x,y})^2 )^{\beta} \tag{1}\]정리하자면 ReLU와 MaxPool을 사용하기 때문에 입력 값을 그대로 출력하는 특성상 매우 높은 한 픽셀 값이 주변에 많은 영향을 미치게 될 것이고 이를 방지하기 위해 다른 feature map에 같은 위치에 있는 픽셀 끼리 정규화를 해주는 것입니다.
Comments