
U-Net
21 Jan 2020 | visionU-Net : Convolutional Networks for Biomedical Image Segmentation
Introduction
논문 제목에서 알 수 있듯 생물 의학적 Image segmentation에 대한 논문입니다.
대부분의 CNN은 single label image에 대한 classfication 문제를 해결하는데 사용됩니다.
그러나 이 논문에서는 localization에 대한 정보를 원하고 있습니다.
즉, class label이 each pixel에 할당되어야 한다고 주장합니다.
예를 들면 특정 세포의 위치에 할당된 label 생각해 볼 수 있겠죠..?
또한 의료 이미지는 항상 데이터 수가 모자란 점을 지적하고 있습니다.
이 논문에서 제안하는 network는 patch 라는 단위를 사용하는데, 기존의 CNN에서 sliding window에 해당하는 영역과 비슷한 느낌으로 생각하면 될 것 같습니다.
기존의 network들은 CNN 연산중 sliding window 방식에서 기존에 검증이 끝난 부분을 또 다시 sliding 하며 지나가기 때문에 불필요한 검증이 많은데 patch 방식을 활용해 이러한 과정을 생략하고 patch에 맞게 검증을 하여 속도가 더 빨라졌습니다.
network architecture에서 fully connected layer가 없는 것도 속도 향상에 도움이 됐겠죠?
또한 Localization accuracy와 use of Context의 trade-off에 빠지지 않습니다.
architecture에서 왼편(Contracting Path)에서 얻은 context information을 바탕으로 더욱 정확한 localization을 가능하게 합니다.
Architecture
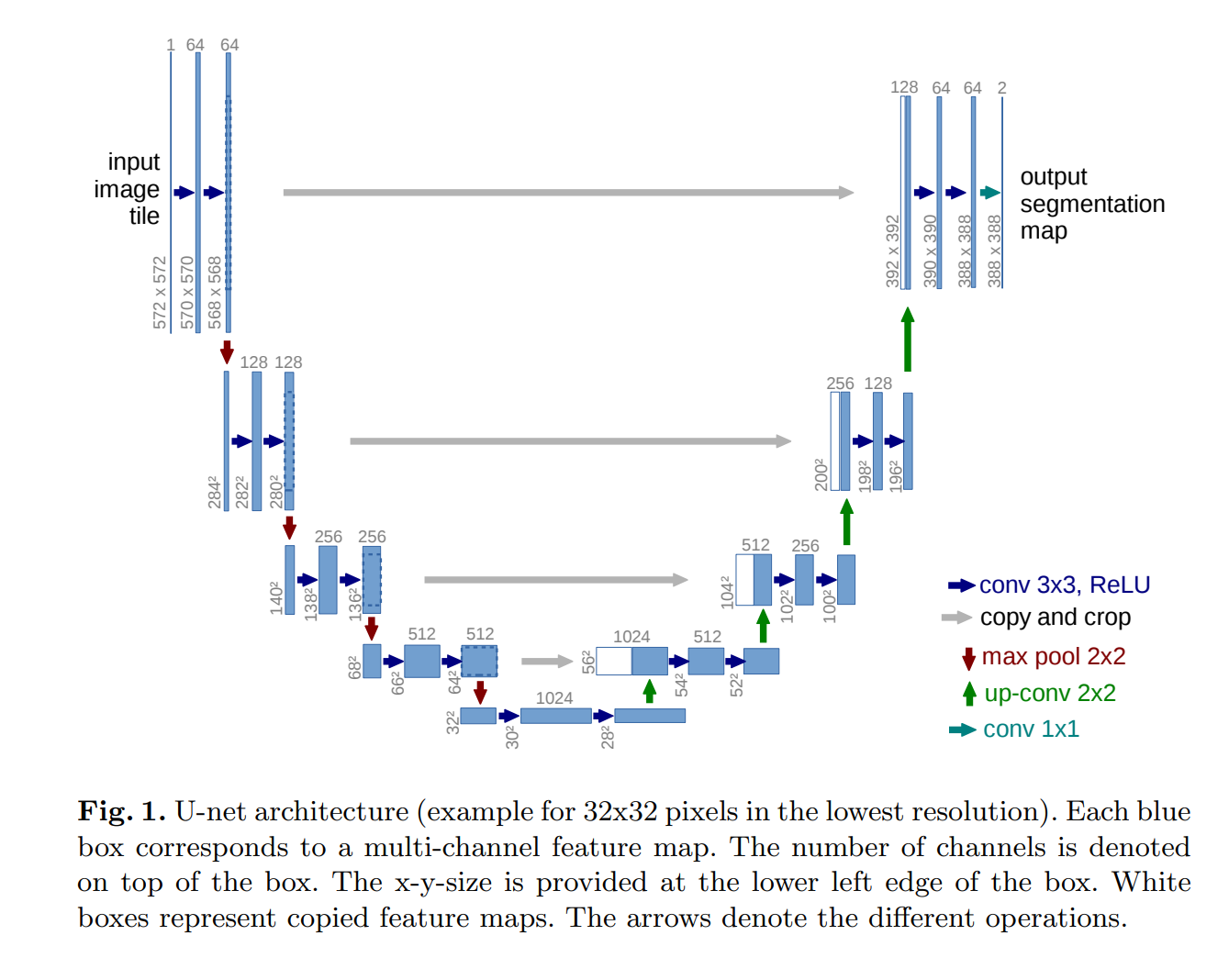
U-Net은 Fully Convolutional Network 구조를 사용하고 있습니다.
위 그림에서 볼 수 있듯 파란색 박스는 multi-channel feature map, 하얀색 박스는 feature map의 사본을 의미합니다.
U 형태를 기준으로 왼쪽편은 기존의 CNN과 유사합니다.
왼쪽편에 있는 architecture를 앞으로 Contracting Path라고 부르겠습니다.
3x3 Conv layer 2개로 구성되며 4번의 block을 거쳐 내려옵니다. padding이 없기 때문에 max pooling을 거칠수록 size가 점점 줄어드는 것을 볼 수 있습니다.
기존의 CNN과 마찬가지로 Contracting Path에서는 Conv layer를 거쳐 feature map을 통해 image에 대한 Context information을 얻을 수 있습니다.
U 형태의 오른쪽은 Expansive Path 라고 부릅니다.
Expansive Path에서는 Contracting Path의 Output인 feature map을 Upsampling 하여 기존의 image로 reconstruction 합니다. 또한 얻은 Context Information을 바탕으로 더 정확한 Localization을 할 수 있습니다.
가로로 횡단하는 화살표(Skip connection)좌 우를 보면 size가 맞지 않는 것을 볼 수 있는데 왼쪽의 사본을 (하얀색 박스)오른쪽으로 보낼 때 conv연산에 의해 가장자리 부분의 pixel information의 손실에대한 보정을 위하여 중앙 부분만 crop해서 보냅니다.
이 Skip connection에 의해 encoder - decoder 구조에서 필연적으로 발생하는 정보의 손실을 최소화 할 수 있게 되었습니다.
가장 마지막 layer는 1x1 conv layer 인데 64개의 component feature vector를 desired number of class 에 mapping합니다.
Overlap-tile
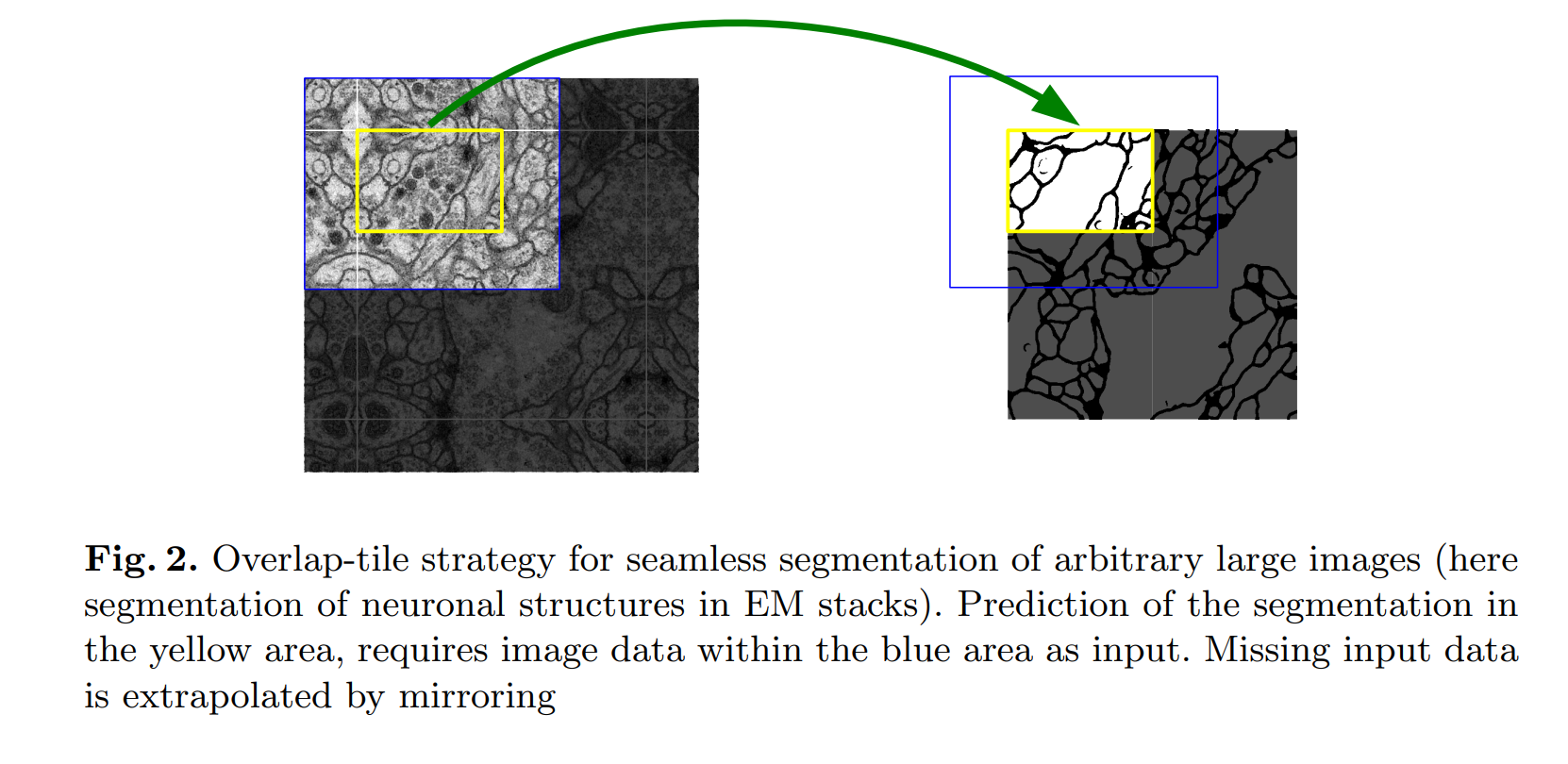
위 그림에 잘 설명 되어 있듯이 blue area를 통해 yellow area의 segmentation을 predict한 것을 알 수 있습니다.
Missing data는 mirroring(mirror padding)을 통해 보간했습니다.
즉, 위 그림처럼 경계의 바깥부분을 zero-padding 하는 것이 아닌, 원본을 그대로 Mirroring합니다.
Augmentation
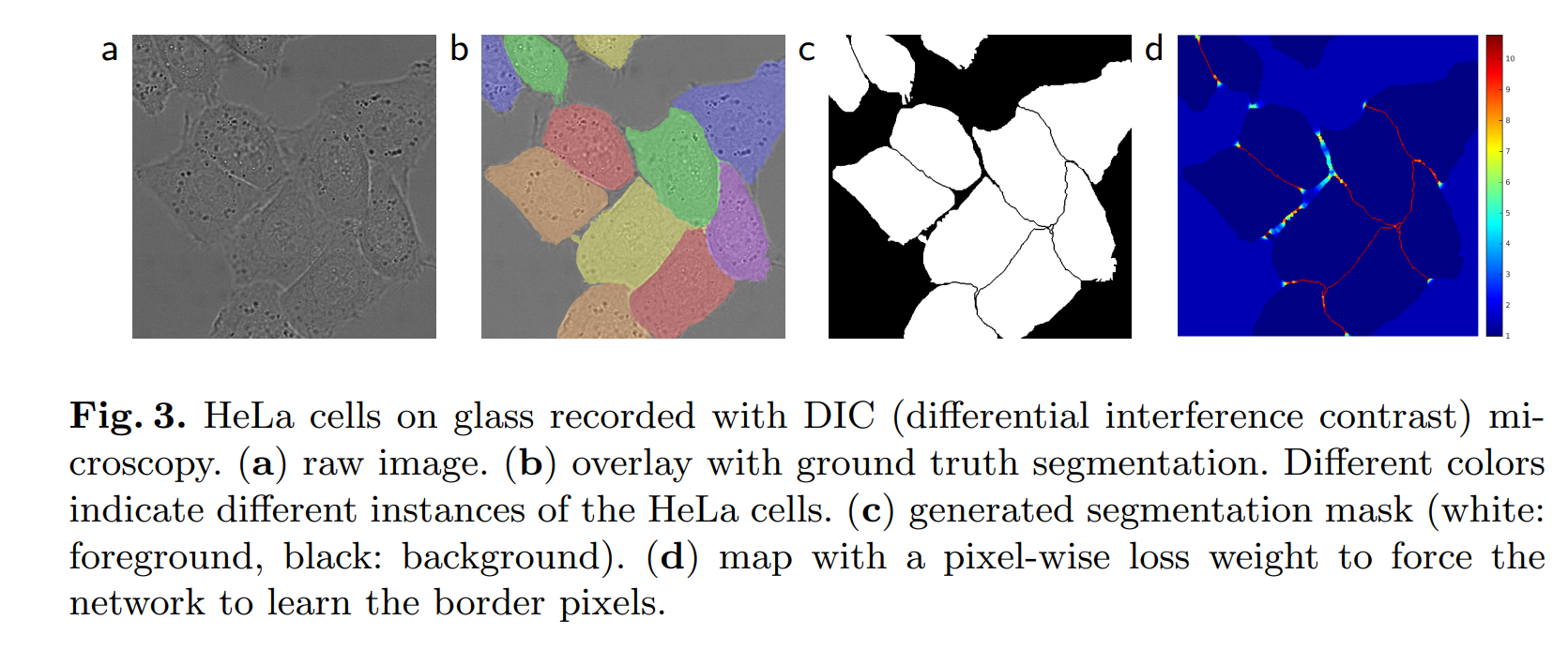
- Elastic Deformation : 적은 수의 이미지를 효과적으로 학습하기 위해 사용한 방식입니다.
- Weighted Cross Entropy + Data Augmentation : 같은 클래스가 서로 인접해있는 케이스의 경우 셀과 배경을 각각 구분하는 것은 쉽지만 셀 각각을 instance segmentation 하는 것은 어렵습니다. 그래서 이 논문에선 반드시 instance의 경계와 경계 사이가 배경이 되도록 처리합니다.(틈을 만들기 위해서) 이를 처리하기위해 Morphological 연산을 사용합니다.
Comments