
CRAFT
10 Jan 2020 | ocrCharacter Region Awareness for Text Detection
1. What is OCR?
OCR은 크게 Text Localization과 Text Recognition으로 나뉘는데,
저희가 다룰 CRAFT모델에서 Localization은 Segmentation-based 방식
(pixel단위로 접근하여 각 pixel이 글자 영역에 속할 확률 & 특정 pixel이 글자 영역에 속할 때 인접한 8개의 pixel이 글자 영역에 속할 확률 두가지를 활용하여 글자 영역끼리 Grouping하는 방법)
Recognition은 Attention-based 방식
(RNN의 현재 step의 결과를 뽑기 위해서 이전 step의 정보들 중 어떤 step의 정보를 중점적으로 볼 것인지 판별하는 방식, 가변길이의 시퀀스를 생성함)을 사용합니다.
2. Introduction
CRAFT 모델은 일본어 OCR을 위해서 만들어 진걸로 알고 있습니다.
기존의 OCR 모델들은 Word-level Detection인데
일어의 경우 띄어쓰기가 없어 인식이 힘들다는 문제점이 존재하여
이 문제점을 해결하기 위해 Character-level Detection을 하는 모델입니다.
위에 띄어쓰기를 예시로 들었지만 Word-level Detection의 어려움을 몇가지 더 짚어보자면,
Arbitrary shape text에 대응하기 어려움(Curve, Extremely long, …)
Word 정의 자체의 어려움 등이 있을 것 입니다.
3. Training
그런데 대부분의 논문들은 Word-level이므로 Character level dataset이 존재하지 않습니다. 논문에서는 이 문제를 weakly supervised method로 해결합니다.
우선 Ground Truth Label을 생성해야하는데,
GT는 주어진 이미지에 대응하는 각 pixel별 Region Score와 Affinity Score GT를 필요로 합니다.
Region Score : 주어진 pixel이 글자의 중심일 확률
Affinity Score : 인접한 두 글자의 중심일 확률
Pixel을 개별적으로 레이블링 하는 Binary segmentation map과 달리 Gaussian heatmap으로 character 중심의 확률을 인코딩 합니다.
heatmap을 사용하여 region score와 affinity score 두 가지를 학습합니다.
the label generation pipeline for a synthetic image.
b-box 내의 각 pixel에 대하여 Gaussian distribution value를 직접 계산하는 것은 너무 오래걸립니다.
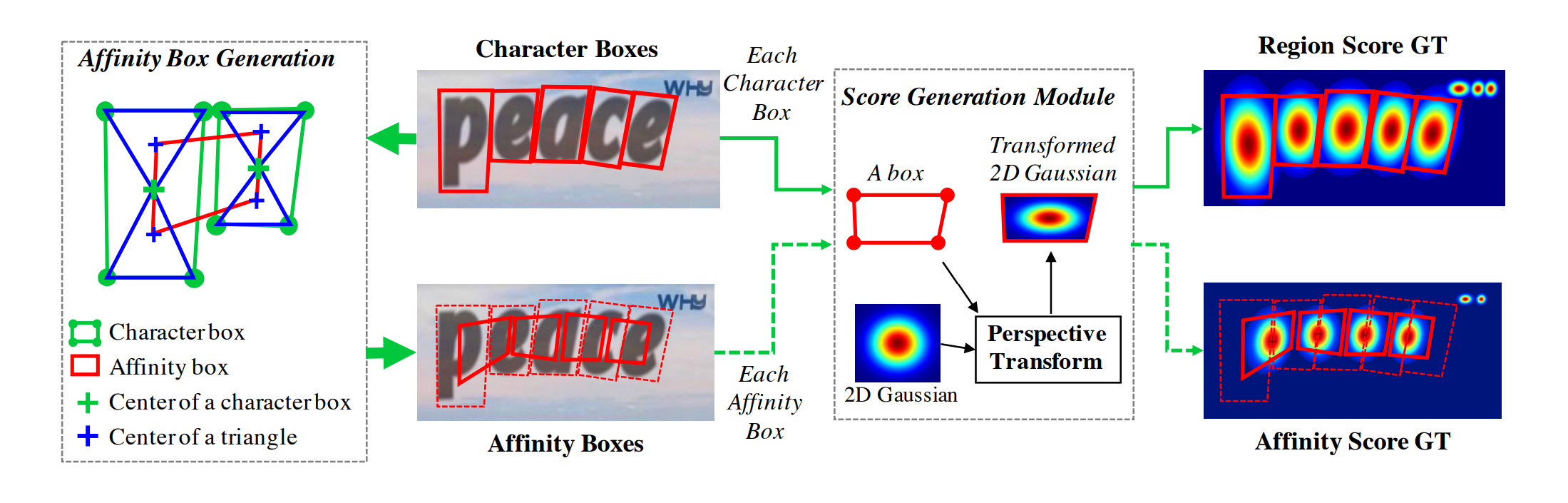
이미지에서 character b-box는 일반적으로 왜곡되므로 다음의 단계를 거쳐 region score와 affinity score 점수 모두에 대한 근거를 근사화하고 생성합니다.
- 2차원 isotropic Gaussian map을 생성한다.(정사각형 형태)
- Gaussian map 영역과 각 character box 사이의 perspective transform을 계산한다.
- Gaussian map 을 box 영역에 맞게 투영(변형)한다.
결론적으로 글자의 중심 pixel을 가지고 Gaussian distribution을 활용해 character b-box를 만들겠다는 것 같은데.. (글자의 중심 pixel일 확률은 어떻게 구하는걸까..?) 나중에 찾아봐야 겠다.
affinity box는 인접한 character box를 통해 다음과 같이 생성된다.
-
c-box의 대각선 교점을 c-box의 중심점으로 한다.
- 중점을 기준으로 생성되는 상삼각, 하삼각형에 각각 중심점을 생성한다.
- 인접한 두 c-box의 상삼각, 하삼각형의 중심점 4개를 연결하여 affinity box를 생성한다.
위에서 생성한 GT를 사용하면 character level detection을 통해 convolutional filters는 전체 text instance 대신 character에만 초점을 맞출 수 있기 때문에 적은 receptive fields를 사용하더라도 모델이 긴 text instance를 충분히 감지할 수 있습니다.
4. Weakly-Supervised Learning
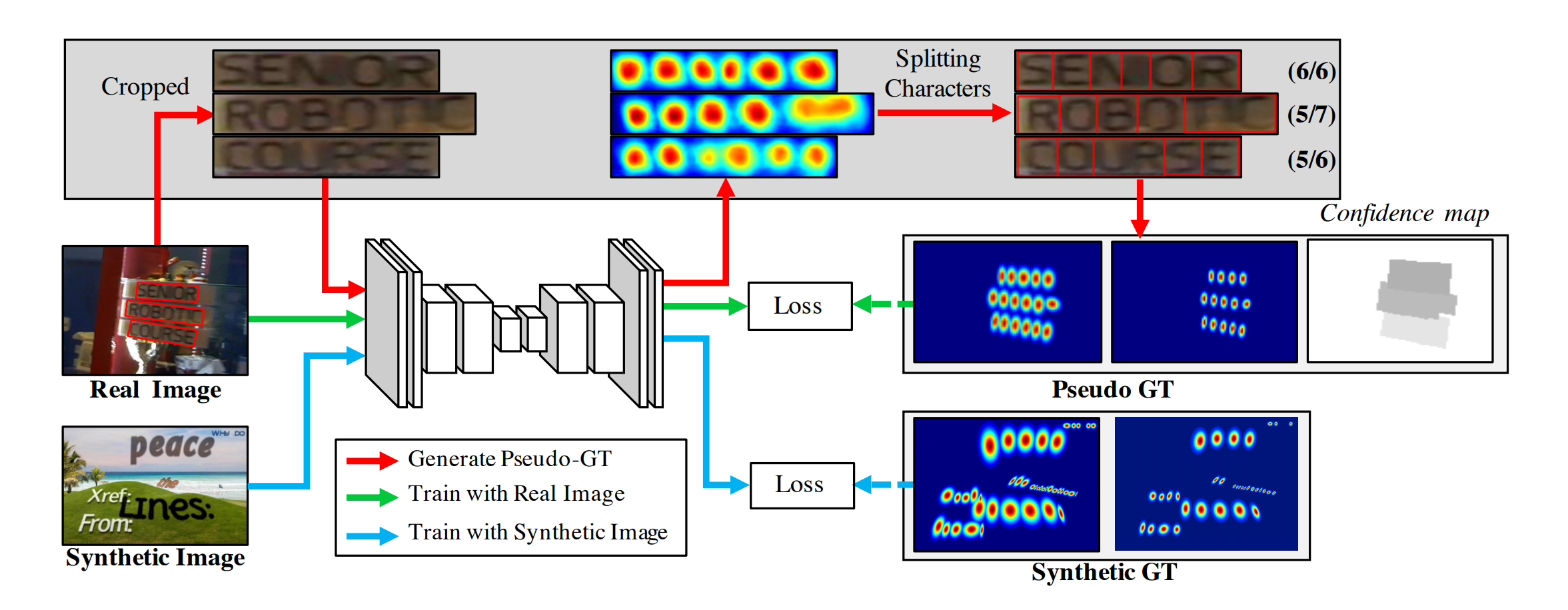
synthetic datasets와 달리 real image에는 일반적으로 word-level annotations이 있습니다. 우리는 위 그림에 요약된 것 처럼 weakly-supervised manner를 통해 각 word-level annotations에서 c-box를 생성합니다.
word-level annotations이 포함된 real image가 제공되면 학습된 임시 모델은 cropped word images의 character region score를 예측하여 c-box를 생성합니다.
임시 모델 예측의 신뢰성을 반영하기 위해서,
각 word box에 대한 the value of confidence map(신뢰도의 값)은 감지 된 characters 수를 GT characters 수로 나눈 비율에 비례하여 계산됩니다.
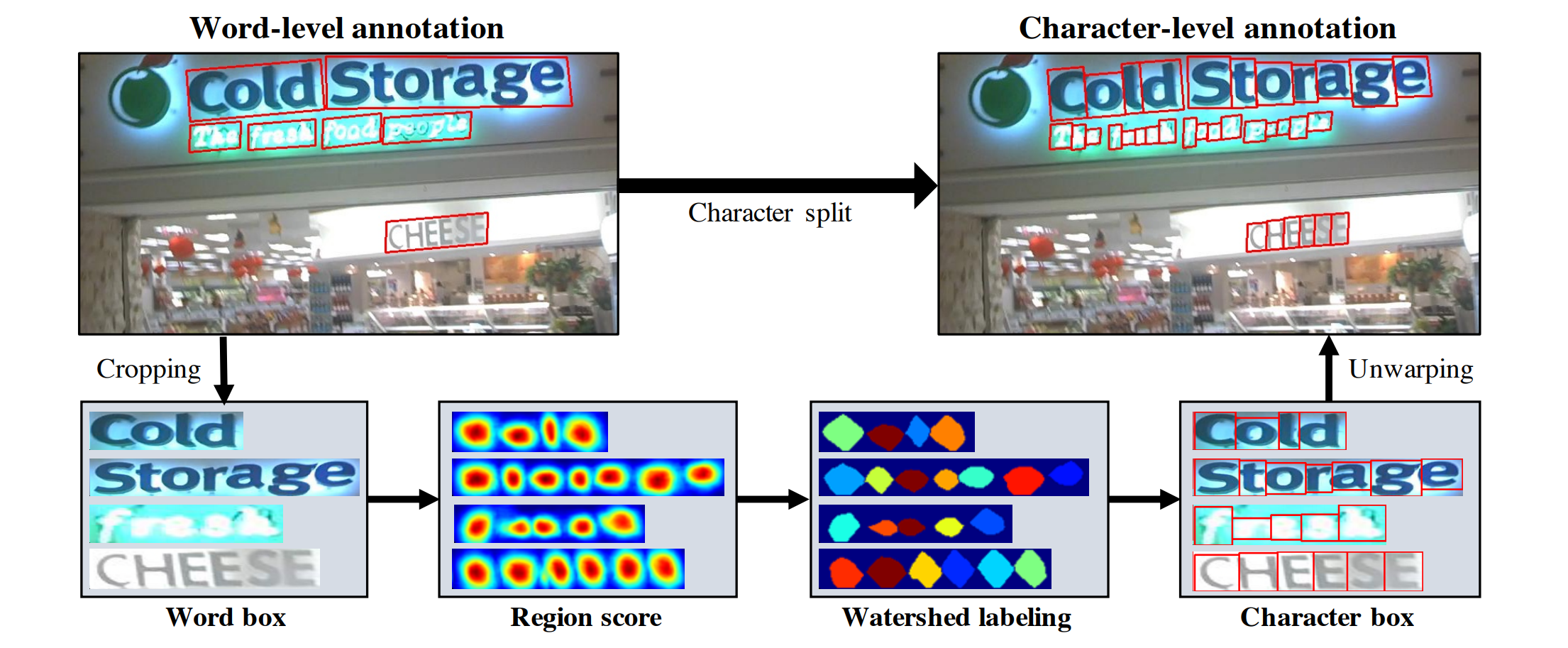
위 그림은 Word-level annotation을 분리하는 절차를 보여줍니다.
- word-level image를 original image로 부터 cropped
- 현재까지 훈련된 모델(임시모델)로 region score를 예측
- watershed algorithm을 character region을 분할 (character bounding box를 만드는데 사용함)
- 마지막으로 cropping step의 inverse transform을 사용하여 c-box의 좌표를 original image 좌표로 transform
우리는 weak-supervised learning을 사용하기 때문에 incomplete pseudo-GT를 사용하여 학습할 경우 모델이 부정확한 region score로 인해 output이 character region내에 blurred하게 표시될 수 있습니다.
이를 방지하기 위해 모델에서 생성된 각 pseudo-GT의 quality를 측정해야 합니다.
우리는 이를 위해 word length를 사용할 수 있습니다.
$l(w)$ : word length
$R(w)$ : bounding box region
$l^c(w)$ : character bounding box and their corresponding length of characters
$s_{conf}(w)$ : confidence score (실제 박스 수와 추정 박스 수가 같을 때 1, 다를 때 0에 가까워짐)
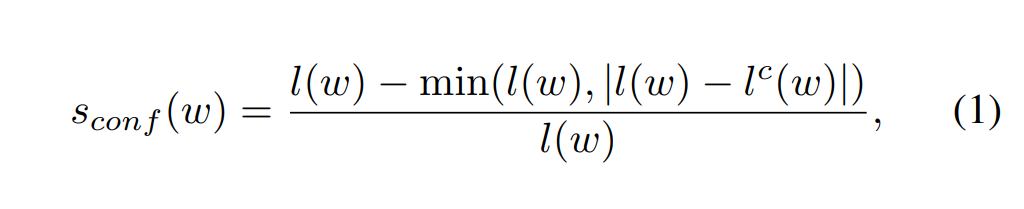
딱 봐도 절댓값 안의 식이 같다면(실제 박스 수 = 추정 박스 수) min값이 0이되므로 전체 식이 1이 되는 것을 알 수 있습니다.
$S_c$ : pixel-wise confidence map ( 각 pixel마다의 confidence 값, $S_c$map 은 pixel마다 word length를 기반으로 하여 0~1 confidence 값을 지니게 됩니다.)
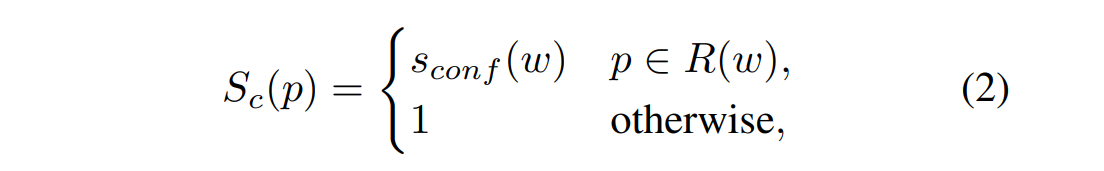
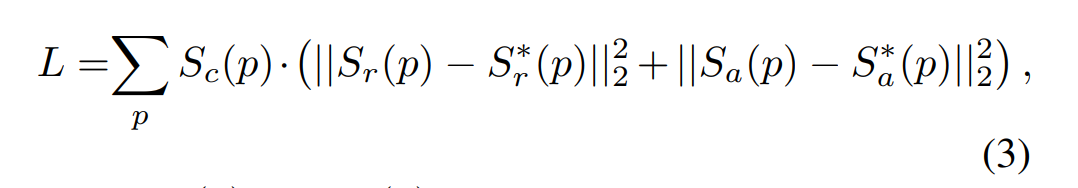
$S_r^*(p)$ : Pseudo-GT로 생성된 region score
$S_a^*(p)$ : Pseudo-GT로 생성된 affinity map
따라서 Lossfunction $L$은 original image로 부터 생성된 Score map과 Pseudo GT로 부터 생성된 Score map 사이의 차이가 없도록 하며 앞서 말했던 Weak-supervised learning으로 인한 신뢰도를 높여주기 위해 Confidence를 곱하는 것으로 해석할 수 있습니다.
Comments