
What is markov?
08 Aug 2020 | Reinforcement Learning마르코프 체인이란?
마르코프 체인은 마르코프 성질을 지닌 이산 확률 과정(Discreate Stochastic Process)을 의미합니다.
시간에 따른 계의 상태 변화를 나타내며, 매 시간마다 계는 상태를 바꾸거나 같은 상태를 유지합니다. 마르코프 성질은 과거와 현재 상태가 주어졌을 때의 미래 상태의 조건부 확률 분포가 과거 상태와는 독립적으로 현재 상태에 의해서만 결정된다는 것을 뜻합니다.
마르코프 가정
\[P(o_t\vert o_{t-1},...,o_1) = P(o_t\vert o_{t-1})\]강화학습에서 마르코프 가정을 사용하는 이유는 뭘까요?
충분한 정보가 담긴 State가 있으면 이전의 History는 사실 필요가 없습니다.
예를 들어 자율 주행을 할 때 필요한 정보에 속도, 날씨, 주변상황이 있으면 현재 상태를 기반으로 다음 틱을 예측 가능하지만, 저희에게 ‘현재 위치’ 라는 정보만 있다면, 과거 State의 위치를 통해 time step당 이동한 거리를 바탕으로 속력을 구해야겠죠? 이런 경우는 마르코프가 아니게 됩니다.
또 다른 예시를 들어보면 현재의 혈압을 통해 약을 투약하는 것은 어떤가요? 현재의 ‘혈압’은 운동을 해서 오른건지, 원래 높은건지 알 수 없습니다. 즉 정보가 부족합니다. 이 또한 마찬가지로 합리적인 선택을 하려면 과거 State의 정보를 끌어 써야 하므로 마르코프하지 않습니다.
마르코프 성질
\[P(S_{t+1}\vert S_t) = P(S_{t+1}\vert S_1,...,S_t)\]
현재 State는 충분한 정보를 가지고 있으므로 이전 States는 버려도 된다.(독립적이다.)
i.e. The state is a sufficient statistics of the future
마르코프 모델
마르코프 모델은 위의 가정 하에 확률 모델을 생성한 것으로, 가장 먼저 각 상태를 정의합니다.
상태는 $V={v_1,…,v_m}$으로 정의하고, 상태 전이 확률을 정의합니다. $a_{ij}$는 $v_i$에서 $v_j$로 이동할 확률을 뜻합니다. 식으로는 다음과 같이 나타냅니다.
\[a_{ij}=P(o_t=v_j\vert o_{t-1}=v_i) \\ a_{ij}>0\: and\: \sum\limits_{j=1}^m a_{ij}=1\]상태와 상태 전이 확률을 정리하여 diagram으로 아래와 같이 표현 할 수 있습니다.
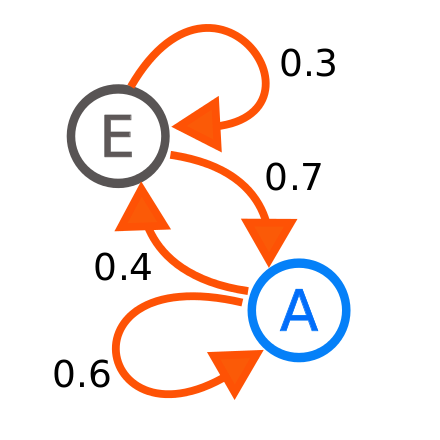
Markov reward process
MRP는 마르코프 프로세스<$S$, $P$>의 각 상태에 리워드를 추가하여 확장한 것입니다.
아래와 같이 정의된 <$S,P,R,\gamma$>로 표현 가능합니다.
- $S$: state의 집합입니다. 바둑판의 현재 상태에서 돌들의 위치, 미로 탈출 문제에서 현재의 위치 등을 나타냅니다.
- $P$: 각 요소가 $p(s’\vert s)=Pr(S_{t+1}=s’\vert S_t=s)$인 집합입니다. $p(s’\vert s)$는 현재 상태 $s$에서 $s’$로 이동할 확률을 의미하며 transition probability라고 합니다.
- $R$: 각 요소가 $r(s) = E[R_{t+1}\vert S_t=s]$인 집합입니다. $r(s)$는 상태 $s$에서 얻는 리워드를 뜻합니다.
- $\gamma$: 즉각적으로 얻는 리워드와 미래에 얻을 수 있는 리워드 간의 중요도를 조절하는 변수입니다. 주로[0,1]사이의 값을 가지며, discount factor라고 불립니다.
저는 단순히 미래의 리워드는 불확실하니까 factor를 추가해준다…라고 이해했는데 실버 교수님께서 말씀하시길 수학적으로 편리하다고 하십니다.
Discount factor로 인해 수렴성이 증명이 된다고 하십니다. 수렴이 되야 거리함수를 정의할 수 있어서가 아닐까 조심스럽게 넘겨짚어봅니다.
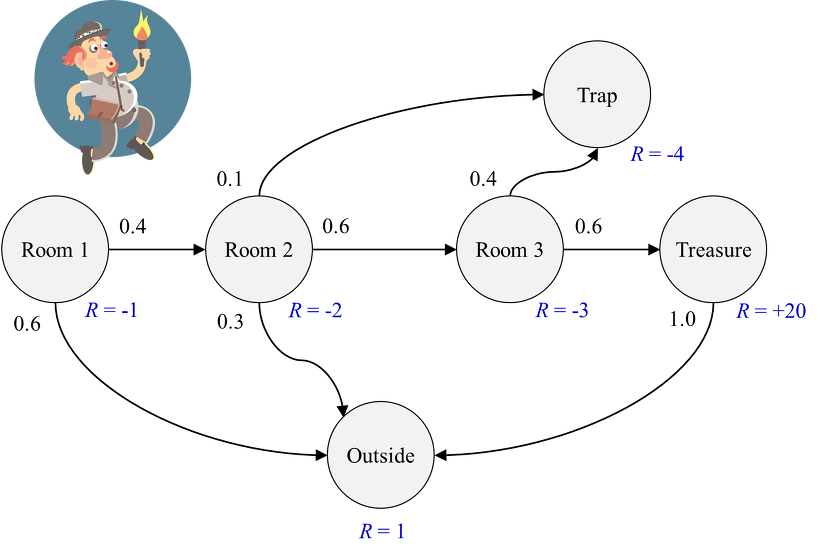
return $G_t$는 $t$시간 이후 얻을 수 있는 리워드의 합을 의미하며 $\gamma$를 통해 다음과 같이 정의됩니다.
\[G_t = R_{t+1} + \gamma R_{t+2} +... = \sum\limits_{k=0}^{\infty} \gamma^kR_{t+k+1}\]State-value function
state value function $v(s)$는 state $s$에서 시작했을 때 얻을 수 있는 return의 기댓값을 의미하며 다음과 같이 정의됩니다.
\[v(s)=E[G_t\vert S_t=s]\]$v(s)$는 궁극적인 목표를 달성하는데 있어서 state $s$가 얼마나 좋은 상태인지를 나타낸다고 볼 수 있습니다.
또한 같은 State에서 시작하더라도 이후에 어떻게 샘플링하느냐에 따라 값이 다를 수 있기 때문에 기댓값을 붙여줍니다.
$v(s)$는 다음과 같이 재귀적인 형태로 표현될 수 있으며 이를 Bellman equation이라 합니다.
\[v(s)=E[R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... \vert S_t=s] = E[R_{t+1} + \gamma v(S_{t+1})\vert S_t =s]\] \[v(s)=R_{t+1} + \gamma\sum\limits_{s' \in S}p(s'\vert s)v(s')\]아무튼 벨만 방정식은 선형이므로 다음과 같이 풀 수 있습니다.
\[v=R+\gamma Pv\] \[(I-\gamma P)v = R\] \[v = (I-\gamma P)^{-1}R\]위 정의에서 Markov reward process는 $P,R,\gamma$를 다 주니까 저 식을 풀 수 있습니다.
Markov Decision Process
MDP는 MRP에서 decision이 추가된 것이며 $<S, A, P, R ,\gamma>$로 구성됩니다.
$A$는 action의 집합입니다.
\[P^a_{ss'} = P(S_{t+1}=s'\vert S_t =s,A_t=a)\]MRP에서는 state마다 리워드를 받지만 MRP에서는 action마다 리워드를 받고 action을 통해 바로 state로 가는 것이 아니라 각 action에는 확률이 존재합니다.
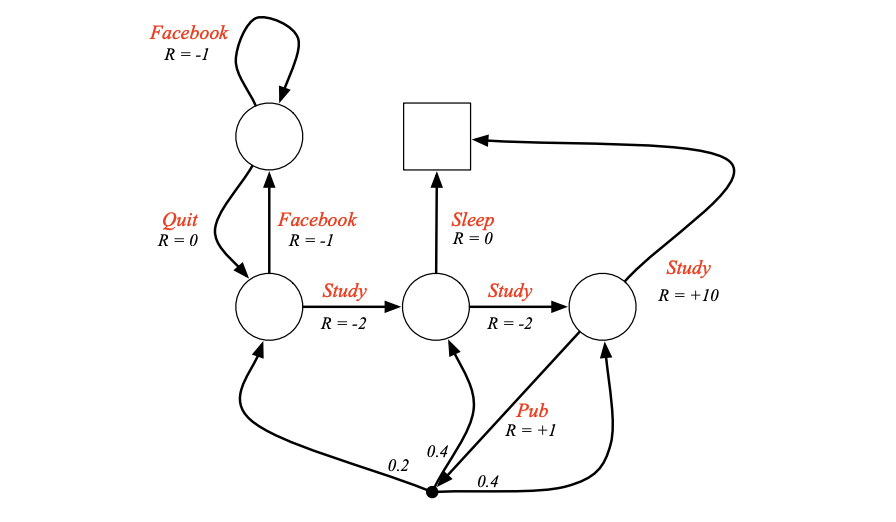
MRP에서는 Policy가 존재하지 않습니다. 그냥 state에 있으면 자동으로 어떤 확률에 의해 다음 state로 넘어갔습니다. 하지만 MDP는 action에 의해 넘어가므로 Policy가 필요합니다.
\[\pi(a\vert s) = P(A_t=a\vert S_t=s)\]policy는 주어진 state에서 할 수 있는 action들의 확률 분포 입니다. Agent의 행동을 정해주며 MDP policy들은 history가 아닌 현재 스테이트에 의존합니다.
MDP(는 환경입니다.) 에서 어떤 policy(에이전트) $\pi$를 가지고 움직인다고 가정합시다.
policy를 고정하면 MDP를 MP $<S,P^{\pi}>$로 action 없이 풀 수 있습니다.
\[P_{s,s'}^{\pi} = \sum\limits_{a\in A} \pi(a\vert s)P_{ss'}^a\] \[R_s^{\pi} = \sum\limits_{a\in A}\pi(a\vert s)R_s^a\]좀 어려운 내용이라고 강의에서도 언급하니까 제가 이해한대로 말해보자면,
어쨋든 각 state에서 각 action을 할 확률$(\pi(a\vert s))$ x 각 state에서 각 action을 통해 다음 state로 갈 확률$(P(s’\vert s,a))$을 모두 더해주면 그 policy에서 s -> s’로 갈 확률이 됩니다.(어떻게보면 당연한 얘기를 어렵게하는 것 같습니다.)
어쨋든 policy가 고정되면 저렇게 MDP -> MP or MRP로 바꿀 수 있다!
Value Function
저희는 이제 MDP에서 policy가 생겼으므로 value function을 정의할 때도 $\pi$가 필요합니다.
아래는 state-value function입니다.
\[v_{\pi}(s) = E_{\pi}[G_t\vert S_t=s]\]action-value function은 어떻게 될까요?(state $s$에서 Action $a$를 했을 때 policy $\pi$를 따라서 한 에피소드가 끝날 때 return의 기댓값)
\[q_{\pi}(s,a) = E_{\pi}[G_t\vert S_t=s,A_t=a]\]이제 이 두 관계를 벨만 방정식을 통해 표현해 봅시다.
아래는 State-value function의 예시입니다.
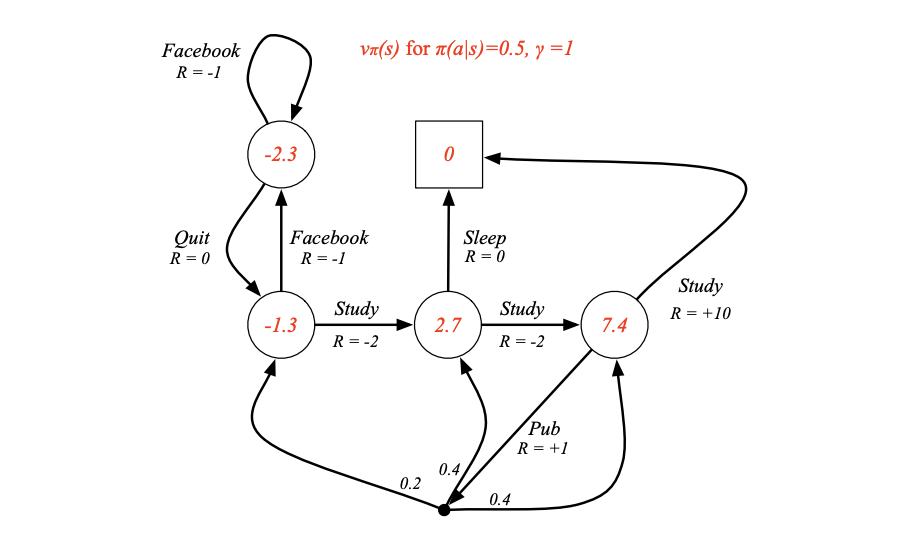
벨만 기댓값 방정식을 통해 수식으로 나타내봅시다.(optimal 버전도 있음!)
\[v_{\pi}(s) = E_{\pi}[R_{t+1} + \gamma v_{\pi}(S_{t+1})\vert S_t=s]\]한 스텝을 가고, 그 다음 state부터 $\pi$를 따라 가는 것과 같다.
action-value function도 유사하게 분해 가능합니다.
\[q_{\pi}(s,a) = E_{\pi}[R_{t+1}+\gamma q_{\pi}(S_{t+1},A_{t+1})\vert S_t=s,A_t=a]\]\[v_{\pi}(s) = \sum\limits_{a\in A}\pi(a\vert s)q_{\pi}(s,a)\]s에서 a를 해서 리워드를 하나 받고, 다음 state부터 $\pi$를 따라가는 것과 같다.(다음 액션은 $\pi$로 정해짐)
state 에서 action을 할 확률 들이 있고(policy), action을 했을 때 action value function이 $q$니까, 걔들의 가중치 합이 $v$이다.
좀 어려운데 그냥 action이 없다고 가정하려면 모든 action에 대해 action-value function을 계산해주면? 되니까 뭔가 marginalize?처럼 각 action에 대해서 밀어버리는 느낌으로 이해했다.
한줄 요약 : state s에서 action a를 했을 때 policy $\pi$를 따라서 게임을 끝까지 진행하면 얻을 수 있는 value
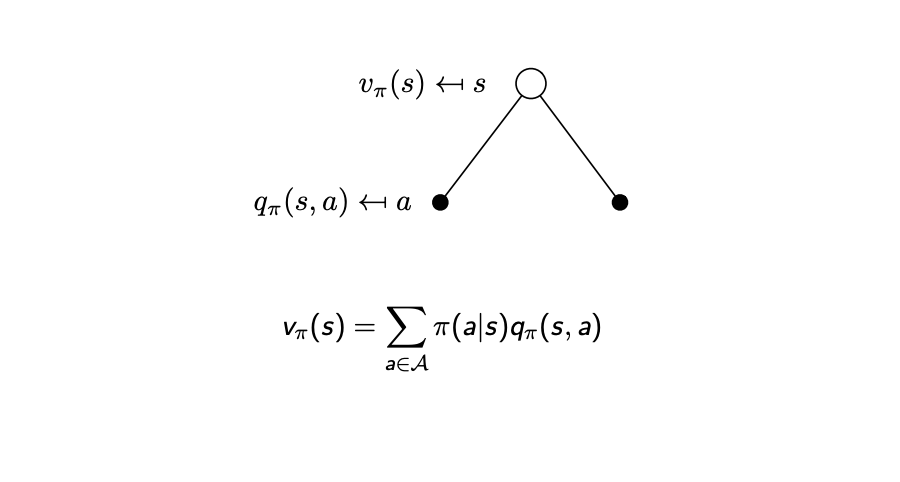
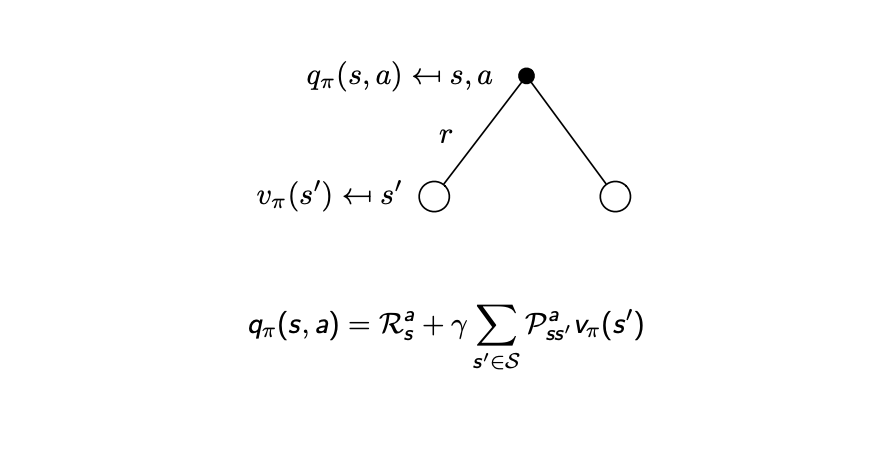
우선 위 식의 원래 형태는 $R_{t+1}+\gamma q_\pi(S_{t+1},A_{t+1})$이다. (이젠 익숙해야한다.)
밑에 그림을 보면 좀 이해가 쉬운데 각 action에서 다음 state(s’)로 갈 확률 x 그 state(s’)에서의 value를 더하고 s에서의 Reward를 더해준다.
벨만 방정식의 재귀적인 형태를 떠올려보자(첫 줄에 적은 식). 우선 한 스텝을 진행하고 거기에 대한 reward를 받은 뒤 다음 스텝에 대한 value를 더 하는 것으로 해석 가능하다.
$P^a_{ss’}$는 action후에 s’에 떨어질 확률이고, $v_\pi(s’)$은 떨어진 state $s’$에서 value function이다.
$v$에 나오는 $q$자리에 위 식을 대입해 봅시다.
\[v_{\pi}(s) = \sum\limits_{a\in A}\pi(a\vert s)(R_a^s + \gamma \sum\limits_{s' \in S}P_{ss'}^a v_{\pi}(s'))\]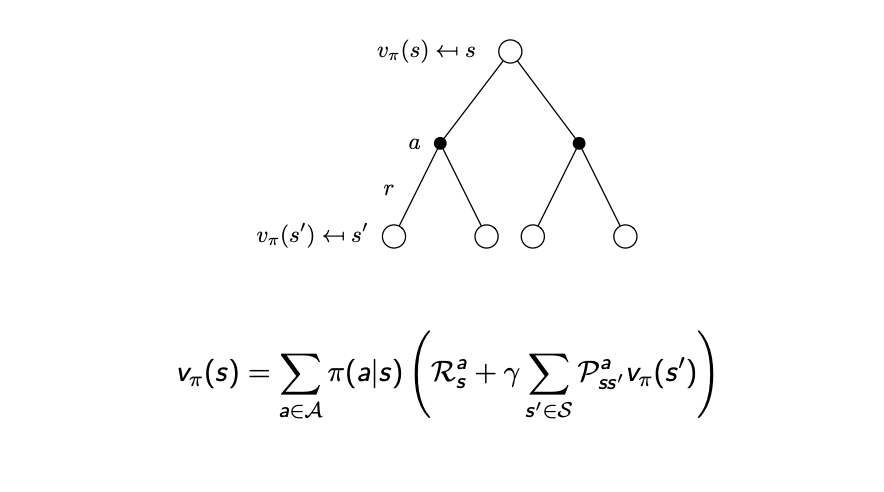
당황하지 말고 천천히 해석해보자.
$v(s)$는 각 state에서 action을 할 확률을 갖고 있고, action을 하여 도착한 state에서 action-value function을 곱해준다. 여기서 action-value function이 뒤에 나오는 괄호 안의 식으로 바뀔 수 있다.
괄호 안의 식을 해석해보자.(어차피 바로 위에 적은 내용을 v에 대해 다시 해석하는 것이다.)
우선 리워드를 하나 받는다. $R^a_s$
action 후에 s->s’에 떨어질 확률 x s’에서의 value function을 곱해준다.
여기서 s’에 떨어질 확률은 MDP에서 트랜지션 매트릭스와 동일하다.
이번엔 $q$에 $v$ 자리에 식을 대입해봅시다.
\[q_{\pi}(s,a) = R_s^a + \gamma \sum\limits_{s' \in S}P_{ss'}^a \sum\limits_{a\in A}\pi(a'\vert s')q_{\pi}(s',a')\]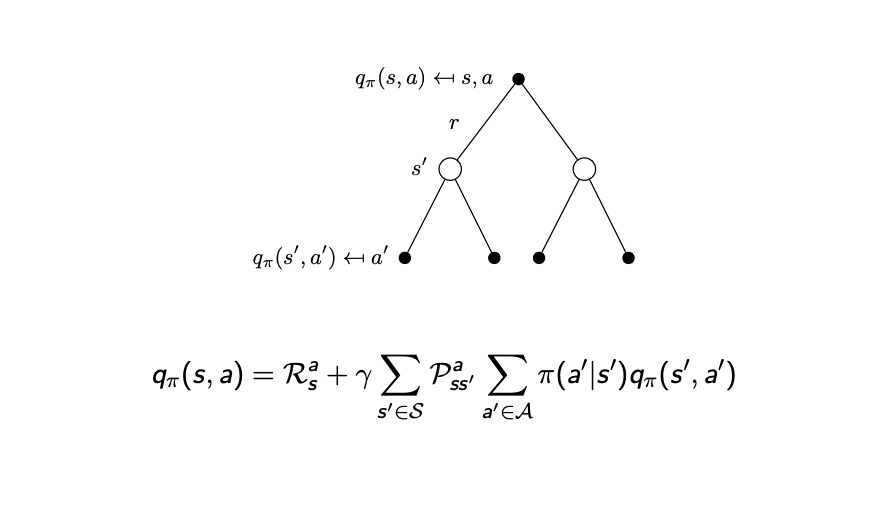
우선 state s에서 Reward를 하나 받습니다. $R^a_s$
action a를 통해 state s’에 떨어질 확률과, 그 state s’에서의 actionvaluefunction을 모두 곱해서 더해줘야합니다.
Comments