
RL introduction
06 Aug 2020 | Reinforcement LearningWhat is Reinforcement Learning?
- Supervisor가 없다. 단순히 reward를 maximize하는게 목적. 어떤 행동을 해야 reward가 높아지는지 알려주지 않기 때문에 모델이 계속 시도하면서 학습함. 이로 인해 사람이 찾지 못한 Global Optimal에 도달할 수 있음
- Feed back이 지연될 수 있음. 즉, 어떤 액션이 리워드를 높이게 야기한건지 알기 어려움. 예를 들어 아이스크림을 10개나 먹어도 괜찮다가 1시간 후에 배가 아픈 것? 처럼 리워드가 있기 전까지 모든 행동들이 고려 대상이기 때문에(1시간 동안 행동한 것이 배가 아픈 원인일 수도, 아이스크림을 먹은 것이 원인일지 확실하지 않음) 원인을 명확히 찾기 어려움
- Time really matters(Sequential, non iid) 순서가 중요함, 애초에 ‘순차적 선택을 잘 하도록 학습하는 것’ 이 목표이기도 하고, 기존의 ML/DL에서 데이터가 iid라고 가정하지만 강화학습은 아님.
- Agent의 action이 이후 데이터에 영향을 준다.
What is Reward?
Reward: Scalar feedback signal
리워드를 벡터로 놓고싶거나 벡터인 경우 강화학습을 적용하기 어렵다고합니다. 각 벡터의 디멘션 별로 가중치를 적용해 합으로 놓으면 스칼라니까 이렇게 접근은 가능하다고 합니다.
에이전트의 목표는 comulative reward를 최대화 하는 것!
리워드를 계속 greedy하게 탐색하는 것이 아니라 long-term을 잘 봐야합니다.
e.g financial investment, 체스에서 폰 몇마리 주고 퀸 잡기
Terminology
- Agent : 학습시킬 대상(e.g. 모델, 로봇)
- Action : Agent가 취하는 행동 (time step마다 수행)
- Environment : 외부 환경
- Observation : Action 때문에 바뀐 상황에 대한 정보
- Reward : Action마다 얻는 보상
- History : Observation, Action, rewards의 Sequence $h_t={a_1,o_1,r_1,…,a_t,o_t,r_t}$
- State : 다음 액션을 결정하기 위해 쓰이는 정보 (State is function of History $S_t=f(H_t)$)
웹 광고를 위해 강화학습을 사용했다고 합시다.
Agent는 웹에 특정 영역에 광고를 띄우고(Action) 광고 클릭 수(Observation)를 보고 Reward를 얻습니다. 그리고 Reward를 높이는 방향으로 다시 광고를 띄우겠죠?
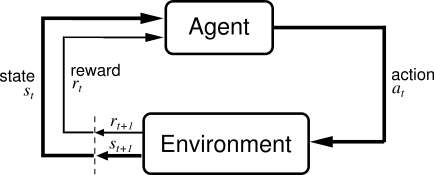
State에 대해 좀 자세히 얘기해봅시다.
Environment state($S_t^e$): Observation, reward를 뱉어내기 위해 사용하는 정보들, 보통 Agent한테 보이지는 않습니다.
게임기를 예로 들어봅시다.
Environment : 게임기
Action : 조이스틱
Observation : 게임화면
Agent : 우리
Reward : 점수
그렇다면 여기서 $S_t^e$는 게임기가 리워드와 게임 화면을 계속 변경해주기 위해 사용되는 정보들을 뜻합니다.(내 위치, 에이전트의 액션, 몬스터의 존재 유무 등등 계산을 위해 필요한 모든 정보들) 그렇기 때문에 에이전트한테 보여질 필요가 없습니다.
Agent state($S_t^a$): 내가 다음 액션을 위해 필요한 정보
에이전트에 따라 이 정보는 많을 수도, 적을 수도 있습니다.
투자자1은 바로 어제의 주식을 보고 오늘 주식을 살지 말지 판단하지만, 투자자2는 다른 비슷한 상황의 모든 주식시장을 고려해서 판단할 경우 투자자2의 $S_t^a$는 엄청 많겠죠? 그리고 이는 히스토리의 함수인 것은 자명합니다. $S_t^a = f(H_t)$
Example
| ♣️ | ♣️ | ♠️ | ♥️ | 🔨 |
|---|---|---|---|---|
| ♥️ | ♣️ | ♠️ | ♠️ | 🍫 |
| ♠️ | ♣️ | ♠️ | ♥️ | ❓ |
위의 예시들은 모두 히스토리로 볼 수 있습니다.
State는 우리가 정의하기 나름입니다. $H={h1,h2,h3}$가 있을 때, 각 히스토리의 $h[1:]$을 State로 정의해봅시다.
- $s1$: {♣️, ♠️, ♥️}
- $s2$: {♣️, ♠️, ♠️}
- $s3$: {♣️, ♠️, ♥️}
이렇게 되면 $s1,s3$가 같으므로 s3에서 우리는 꽝임을 알 수 있습니다.
하지만 각각의 문양이 나온 개수로 State를 정의하면 어떻게 될까요?
- $s1$:{♣️:2, ♠️:1, ♥️:1}
- $s2$:{♣️:1, ♠️:2, ♥️:1}
- $s3$:{♣️:1, ♠️:2, ♥️:1}
이번에는 $s2,s3$가 같으므로 초콜릿을 얻을 수 있습니다. 이처럼 State를 정의하기에 따라 예측 값은 달라집니다.
Major Components of an RL Agent
- Policy : 에이전트의 행동을 나타냅니다. state -> action으로의 매핑
- Derterministic policy: $ a = \pi(s)$
- Stochastic policy: $\pi(a\vert s) = P[A_t=s\vert S_t=s]$
- Value : 미래에 얻을 수 있는 총 리워드의 합을 예측해주는 함수. state가 좋은지 나쁜지 평가해줌.
- $v_{\pi}=E_{\pi}[R_{t+1}+\gamma R_{t+2}+…\vert S_t=s]$
- 어떤 현재 State로 부터 policy $\pi$를 따라 갔을 때 총 얻을 reward의 기댓값 즉, policy가 없으면 Valuefunction이 정의되지 않음.
- 기댓값을 쓰는이유? Environment에도 확률적인 요소가 있고, Stochastic policy인 경우엔 당연히 써야되고!
- Model : 환경이 어떻게 될지 예측.
- $P$ : Predict state
- $R$ : Predict reward
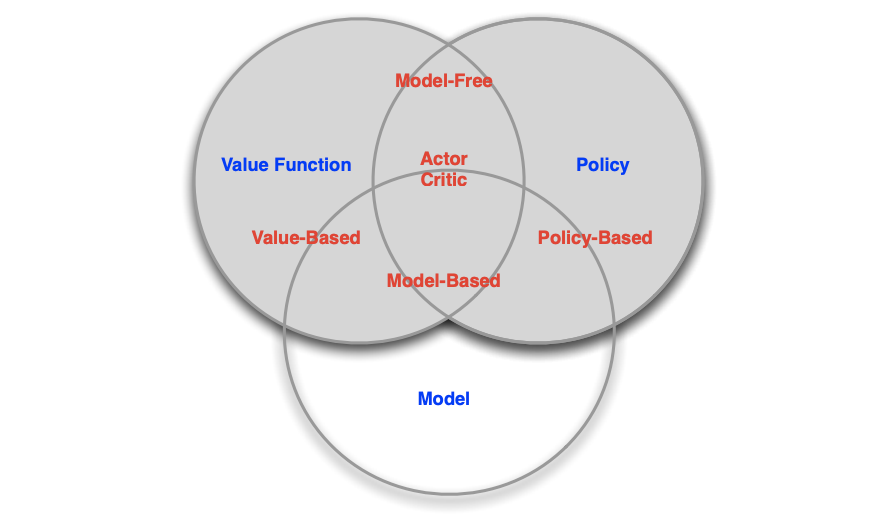
Categorizing RL Agents
- Value Based
- Value Function만 있는 것.(제일 Reward의 기댓값이 높은 함수쪽으로 가면됨)
- Policy Based
- Policy : Policy만 있어도 Agent가 활동 가능
- Actor Critic
- Policy
- Value Function
- Model Free
- Policy and/or Value Function
- Model based
- Policy and/or Value Function
- Model
Comments