
An Overview of Encoding Techniques
27 Jul 2020 | Feature Encoding카카오 아레나 이후로 데이터 컴피티션에 관심이 많이 생겨서 tabular 데이터를 다루는 법에 대해 공부중입니다.
처음 이러한 유형의 컴피티션을 접했을 때 가장 와닫지 않은 부분은 바로 categorical 데이터를 다루는 방법이었습니다.
마침 캐글에 좋은 챌린지가 있어서 1등 노트북을 필사해 봤습니다.
우선 데이터는 아래처럼 생겼습니다.
| id | bin_0 | bin_1 | bin_2 | bin_3 | bin_4 | nom_0 | nom_1 | nom_2 | nom_3 | ... | nom_9 | ord_0 | ord_1 | ord_2 | ord_3 | ord_4 | ord_5 | day | month | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | T | Y | Green | Triangle | Snake | Finland | ... | 2f4cb3d51 | 2 | Grandmaster | Cold | h | D | kr | 2 | 2 | 0 |
| 1 | 1 | 0 | 1 | 0 | T | Y | Green | Trapezoid | Hamster | Russia | ... | f83c56c21 | 1 | Grandmaster | Hot | a | A | bF | 7 | 8 | 0 |
| 2 | 2 | 0 | 0 | 0 | F | Y | Blue | Trapezoid | Lion | Russia | ... | ae6800dd0 | 1 | Expert | Lava Hot | h | R | Jc | 7 | 2 | 0 |
| 3 | 3 | 0 | 1 | 0 | F | Y | Red | Trapezoid | Snake | Canada | ... | 8270f0d71 | 1 | Grandmaster | Boiling Hot | i | D | kW | 2 | 1 | 1 |
| 4 | 4 | 0 | 0 | 0 | F | N | Red | Trapezoid | Lion | Canada | ... | b164b72a7 | 1 | Grandmaster | Freezing | a | R | qP | 7 | 8 | 0 |
5 rows × 25 columns
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 300000 entries, 0 to 299999
Data columns (total 25 columns):
id 300000 non-null int64
bin_0 300000 non-null int64
bin_1 300000 non-null int64
bin_2 300000 non-null int64
bin_3 300000 non-null object
bin_4 300000 non-null object
nom_0 300000 non-null object
nom_1 300000 non-null object
nom_2 300000 non-null object
nom_3 300000 non-null object
nom_4 300000 non-null object
nom_5 300000 non-null object
nom_6 300000 non-null object
nom_7 300000 non-null object
nom_8 300000 non-null object
nom_9 300000 non-null object
ord_0 300000 non-null int64
ord_1 300000 non-null object
ord_2 300000 non-null object
ord_3 300000 non-null object
ord_4 300000 non-null object
ord_5 300000 non-null object
day 300000 non-null int64
month 300000 non-null int64
target 300000 non-null int64
dtypes: int64(8), object(17)
memory usage: 57.2+ MB
그럼 다양한 방법으로 categorical feature들을 encoding 해보겠습니다.
1. Label encoding
사실 가장 흔한 방법이고 가장 익숙한 방법입니다.
모든 범주형 데이터를 숫자로 변경합니다. 예를들어 Grandmaster, master, expert가 있을 때, 각각을 1, 2, 3으로 변환하는 것을 뜻합니다.
이를 사용하기 위해 sklearn에서 모듈을 불러옵니다.
from sklearn.preprocessing import LabelEncoder
train=pd.DataFrame()
label=LabelEncoder()
for c in X.columns:
if(X[c].dtype=='object'):
train[c]=label.fit_transform(X[c])
else:
train[c]=X[c]
| id | bin_0 | bin_1 | bin_2 | bin_3 | bin_4 | nom_0 | nom_1 | nom_2 | nom_3 | ... | nom_8 | nom_9 | ord_0 | ord_1 | ord_2 | ord_3 | ord_4 | ord_5 | day | month | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 5 | 5 | 3 | ... | 1686 | 2175 | 2 | 2 | 1 | 7 | 3 | 136 | 2 | 2 |
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 4 | 3 | 5 | ... | 650 | 11635 | 1 | 2 | 3 | 0 | 0 | 93 | 7 | 8 |
| 2 | 2 | 0 | 0 | 0 | 0 | 1 | 0 | 4 | 4 | 5 | ... | 1932 | 8078 | 1 | 1 | 4 | 7 | 17 | 31 | 7 | 2 |
3 rows × 24 columns
모든 범주형 데이터가 숫자로 바뀐 것을 볼 수 있습니다.
>>>print('train data set has got {} rows and{}columns'.format(train.shape[0],train.shape[1]))
train data set has got 300000 rows and 24 columns
각각의 인코딩에 대해 성능을 비교하기위해 심플한 분류 모델을 만듭니다.
Logistic regression
def logistic(X,y):
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=42,test_size=0.2)
lr=LogisticRegression()
lr.fit(X_train,y_train)
y_pre=lr.predict(X_test)
print('Accuracy : ',accuracy_score(y_test,y_pre))
>>>logistic(train,y)
Accuracy : 0.6925333333333333
2. One Hot Encoding
이것도 NLP를 공부해보셨다면 아주 익숙한 표현일 것입니다.
모든 데이터를 고차원 벡터로 변환하는데 여기서 각 차원은 하나의 값만 1이고 나머지는 모두 0입니다.(아주 sparse 하겠죠?)
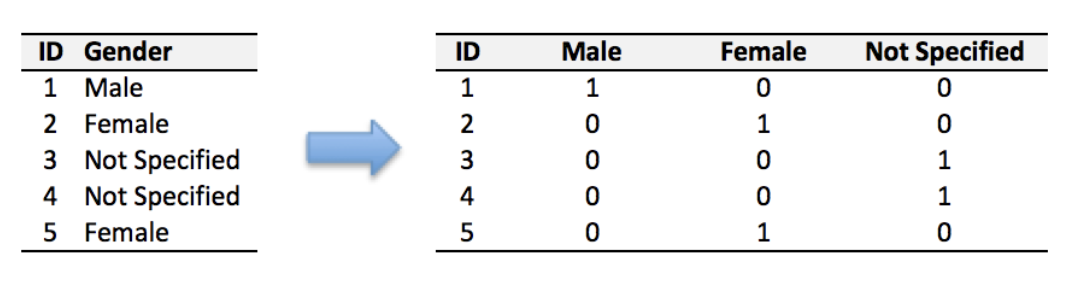
마찬가지로 sklearn 모듈을 통해 변환할 수 있습니다.(pd.get_dummies 라는 함수로도 가능합니다.)
from sklearn.preprocessing import OneHotEncoder
one=OneHotEncoder()
one.fit(X)
train=one.transform(X)
print('train data set has got {} rows and {} columns'.format(train.shape[0],train.shape[1]))
train data set has got 300000 rows and 316461 columns
logistic(train,y)
Accuracy : 0.7593666666666666
보시는 것 처럼 성능이 좋습니다.
하지만 columns수가 24개에서 31만개로 급격히 늘어난 것을 볼 수 있습니다.
3. Feature hashing(a.k.a the hashing trick)
피처 해싱은 ‘one-hot-encoding’스타일로 카테고리를 sparse matrix로 표현하지만 차원이 훨씬 낮은 멋진 기술입니다.
피처 해싱에서는 해싱 함수를 카테고리에 적용한 다음 해당 인덱스로 표시합니다.
예를 들어, ‘New York’를 나타내기 위해 차원 수를 5로 선택하면, H(New York) mod 5 = 3(예를 들어) 이렇게 계산하면 ‘New York’의 표현은 (0,0,1,0,0)이 됩니다.
마찬가지로 우리의 친구 sklearn 모듈을 불러옵니다.
from sklearn.feature_extraction import FeatureHasher
X_train_hash=X.copy()
for c in X.columns:
X_train_hash[c]=X[c].astype('str')
hashing=FeatureHasher(input_type='string')
train=hashing.transform(X_train_hash.values)
print('train data set has got {} rows and {} columns'.format(train.shape[0],train.shape[1]))
train data set has got 300000 rows and 1048576 columns
logistic(train,y)
Accuracy : 0.7512333333333333
보시는 것 처럼 one-hot-encoding으로 변환한 데이터만큼의 성능을 보여주지만 차원 수는 훨씬 낮습니다.
4. Encoding categories with dataset statistics
이제 우리는 모델의 각 피처에 대해 비슷한 범주를 서로 가깝게 배치하는 인코딩을 사용하여 모든 범주에 대한 숫자 표현을 만들어 봅니다.
가장 쉬운 방법은 모든 범주를 데이터 집합에서 나타난 횟수로 바꾸는 것입니다.
이런식으로 뉴욕과 뉴저지가 모두 대도시이면 데이터 세트에서 여러 번 나타날 수 있으며 모델은 이들이 유사하다는 것을 알 수 있습니다.
X_train_stat=X.copy()
for c in X_train_stat.columns:
if(X_train_stat[c].dtype=='object'):
X_train_stat[c]=X_train_stat[c].astype('category')
counts=X_train_stat[c].value_counts()
counts=counts.sort_index()
counts=counts.fillna(0)
counts += np.random.rand(len(counts))/1000
X_train_stat[c].cat.categories=counts
사실 random을 통해서 노이즈를 왜 추가해 주는지는 잘 모르겠다..
아시는 분 계시면 댓글 달아주세요!
변환 후 아웃풋은 아래와 같다.
| id | bin_0 | bin_1 | bin_2 | bin_3 | bin_4 | nom_0 | nom_1 | nom_2 | nom_3 | ... | nom_8 | nom_9 | ord_0 | ord_1 | ord_2 | ord_3 | ord_4 | ord_5 | day | month | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 153535.000826 | 191633.000545 | 127341.000001 | 29855.000948 | 45979.000444 | 36942.000133 | ... | 271.000802 | 19.000267 | 2 | 77428.000323 | 33768.000648 | 24740.000509 | 3974.000977 | 506.000990 | 2 | 2 |
| 1 | 1 | 0 | 1 | 0 | 153535.000826 | 191633.000545 | 127341.000001 | 101181.000962 | 29487.000190 | 101123.000074 | ... | 111.000142 | 13.000710 | 1 | 77428.000323 | 22227.000155 | 35276.000190 | 18258.000088 | 2603.000907 | 7 | 8 |
| 2 | 2 | 0 | 0 | 0 | 146465.000337 | 191633.000545 | 96166.000432 | 101181.000962 | 101295.000088 | 101123.000074 | ... | 278.000558 | 29.000648 | 1 | 25065.000347 | 63908.000426 | 24740.000509 | 16927.000164 | 2572.000012 | 7 | 2 |
3 rows × 24 columns
logistic(X_train_stat,y)
Accuracy : 0.6946166666666667
5. Encoding cyclic features
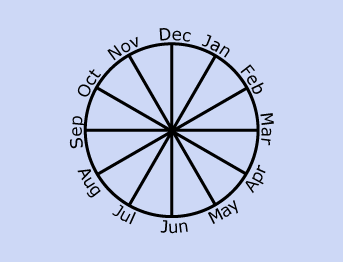
날짜, 시간 등과 같이 주기를 갖는 데이터에 대해서는 삼각 함수를 사용하여 데이터를 2차원으로 변환 할 수 있습니다.
X_train_cyclic=X.copy()
columns=['day','month']
for col in columns:
X_train_cyclic[col+'_sin']=np.sin((2*np.pi*X_train_cyclic[col])/max(X_train_cyclic[col]))
X_train_cyclic[col+'_cos']=np.cos((2*np.pi*X_train_cyclic[col])/max(X_train_cyclic[col]))
X_train_cyclic=X_train_cyclic.drop(columns,axis=1)
X_train_cyclic[['day_sin','day_cos']].head(3)
변환 후 아웃풋은 아래와 같습니다.
| day_sin | day_cos | |
|---|---|---|
| 0 | 9.749279e-01 | -0.222521 |
| 1 | -2.449294e-16 | 1.000000 |
| 2 | -2.449294e-16 | 1.000000 |
주기성을 갖지 않는 나머지 데이터에 대해 one-hot encoding을 적용하여 모델에 넣습니다.
one=OneHotEncoder()
one.fit(X_train_cyclic)
train=one.transform(X_train_cyclic)
print('train data set has got {} rows and {} columns'.format(train.shape[0],train.shape[1]))
train data set has got 300000 rows and 316478 columns
logistic(train,y)
Accuracy : 0.75935
6. Target encoding
Target-based 인코딩은 대상을 통한 범주형 변수의 숫자화입니다.
이 방법에서는 범주형 변수를 하나의 새로운 숫자형 변수로 바꾸고, 범주형 변수의 각 범주를 대상의 확률(범주형) 또는 대상의 평균(숫자인 경우)으로 대체합니다.
아래의 예시를 봅시다.
| Country | Target |
|---|---|
| India | 1 |
| China | 0 |
| India | 0 |
| China | 1 |
| India | 1 |
인도는 전체 레이블에서 3번 나왔고 실제값은 2번 나왔으므로 인도의 레이블은 2/3 = 0.666입니다.
| Country | Target |
|---|---|
| India | 0.66 |
| China | 0.5 |
X_target=df_train.copy()
X_target['day']=X_target['day'].astype('object')
X_target['month']=X_target['month'].astype('object')
for col in X_target.columns:
if (X_target[col].dtype=='object'):
target= dict ( X_target.groupby(col)['target'].agg('sum')/X_target.groupby(col)['target'].agg('count'))
X_target[col]=X_target[col].replace(target).values
변환 후 아웃풋은 다음과 같습니다.
| id | bin_0 | bin_1 | bin_2 | bin_3 | bin_4 | nom_0 | nom_1 | nom_2 | nom_3 | ... | nom_9 | ord_0 | ord_1 | ord_2 | ord_3 | ord_4 | ord_5 | day | month | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0.302537 | 0.290107 | 0.327145 | 0.360978 | 0.307162 | 0.242813 | ... | 0.368421 | 2 | 0.403885 | 0.257877 | 0.306993 | 0.208354 | 0.401186 | 0.322048 | 0.244432 | 0 |
| 1 | 1 | 0 | 1 | 0 | 0.302537 | 0.290107 | 0.327145 | 0.290054 | 0.359209 | 0.289954 | ... | 0.076923 | 1 | 0.403885 | 0.326315 | 0.206599 | 0.186877 | 0.303880 | 0.340292 | 0.327496 | 0 |
| 2 | 2 | 0 | 0 | 0 | 0.309384 | 0.290107 | 0.241790 | 0.290054 | 0.293085 | 0.289954 | ... | 0.172414 | 1 | 0.317175 | 0.403126 | 0.306993 | 0.351864 | 0.206843 | 0.340292 | 0.244432 | 0 |
| 3 | 3 | 0 | 1 | 0 | 0.309384 | 0.290107 | 0.351052 | 0.290054 | 0.307162 | 0.339793 | ... | 0.227273 | 1 | 0.403885 | 0.360961 | 0.330148 | 0.208354 | 0.355985 | 0.322048 | 0.255729 | 1 |
4 rows × 25 columns
logistic(X_target.drop('target',axis=1),y)
Accuracy : 0.6946166666666667
Summary
전체적으로 one-hot 기반이 성능이 좋은 것을 볼 수 있습니다.
저는 딥러닝을 공부하고 -> tabular데이터(ML계열)로 넘어온 케이스기 때문에 왜 인코딩을 저렇게하지? Word2Vec처럼 모델을 이용해서 object타입간의 유사도를 통한 인코딩이 훨씬 성능이 좋지않나? 라고 생각을 했습니다.
그러나 모델의 피처가 클 경우 저런 방법은 현실적으로 너무 비용이 비싸다는 문제가 있을 것 같습니다.(언젠가 저렇게 모델을 통해 피처를 인코딩하거나 전처리하는 방법을 보게되면 그 때 포스팅 하겠습니다.)
| Encoding | Score | Wall time |
|---|---|---|
| Label Encoding | 0.692 | 973 ms |
| OnHotEncoder | 0.759 | 1.84 s |
| Feature Hashing | 0.751 | 4.96 s |
| Dataset statistic encoding | 0.694 | 894 ms |
| Cyclic + OnHotEncoding | 0.759 | 431 ms |
| Target encoding | 0.694 | 2min 5s |
Comments