
Word2Vec(2)
20 Jul 2020 | NLPSoftmax regression & W2V
앞선 내용과 마찬가지로 lovit님의 블로그 글을 정리했습니다.
제가 앞서 정리한 Word2Vec 포스팅과 함께 읽으면 좋으실 것 같습니다.
Summary!
Word2Vec은 softmax regression의 확장이다.
- Softmax regression : 문장의 단어들 X로 문장의 레이블을 예측
- Word2Vec :단어 X로 단어 Y를 예측
Softmax regression은 데이터 (X, Y)를 이용하여, 입력된 input $x$가 클래스 $y$가 될 확률을 최대화 시키는 방향으로 클래스 $y$의 대표 벡터를 coefficient $\beta$에 대하여 학습합니다.
아래 식을 살펴보면 $x$에 대한 $y$의 확률은 $x$의 모든 클래스 종류의 $y_i$와의 내적을 exp 함수에 넣어 non-negative로 만든 뒤, 모든 $exp(\beta_j^Tx)$의 합으로 나눠서 확률 형식을 만듭니다.
$x$가 입력되었을 때, $y$가 가장 큰 확률을 가지기 위해서는 해당 $y$와 $x$의 내적은 가장 크고, 다른 $y_j$와 $x$의 내적은 작아야 합니다.
즉, $x$와 이에 해당하는 클래스의 대표 벡터가 같은 방향이어야 $P(y\vert x)$가 커집니다.
너무 깔끔한 설명이라 굳이 부연 설명이 필요 없을 것 같지만, 그래도 해보자면
기하적으로 내적이 가장 크다는 것은 유사하다고 볼 수 있습니다.(cosine similarity)
즉, 임의의 데이터 $x$가 클래스 $y_t$가 되려면 $y_t$의 클래스 벡터와 가장 유사해야(내적이 가장 커야)하고, 다른 클래스 벡터와는 유사하지 않아야 합니다.(내적이 작아야함.)
$maximize P(y_k\vert x) = \frac{exp(\beta^T_{y_k}x)}{\sum_jexp(\beta^T_jx)}\tag{1}$
W2V는 [a, little, cat, sit, on the, table]이라는 문장이 주어졌을 때, window size 가 5 라면,
[a, little, sit, on] 이라는 스냅샷을 하나 만들고 그 스냅샷으로 cat을 예측합니다.
즉, 4 단어가 X, cat이 Y가 됩니다. 단어를 X로 이용하기 위해 각 단어의 의미 공간에서 위치 좌표, 벡터 값을 이용합니다.
X, Y의 내적이 성립하려면 두 벡터의 차원의 크기가 같아야 합니다. [a, little, sit, on] 4 단어의 평균을 취하면 Y와 같은 차원의 벡터로 만들 수 있습니다.
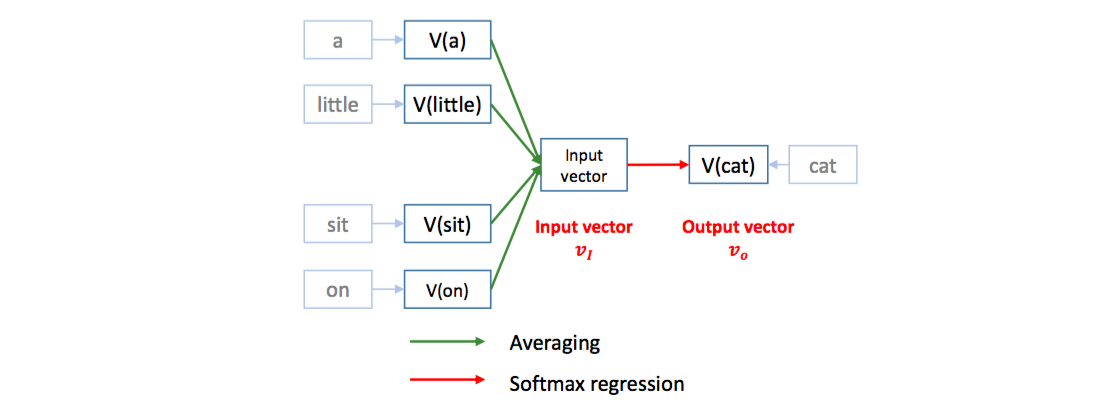
W2V의 학습은 의미 공간에서 각 단어의 위치 좌표를 수정하는 것입니다.
각 단어의 위치 좌표는 random vector로 초기화합니다. 이때는 당연히 위의 공식이 잘 맞지 않는데, $P(cat\vert[a, little, sit, on])$이 커지도록 좌표를 조절해야 합니다.
[a, little, sit, on]의 평균 벡터가 $v_I$라고 하면, ‘cat’의 위치벡터는 $v_I$와 비슷해야 하고, 다른 단어의 벡터는 $v_I$와 달라야 합니다.
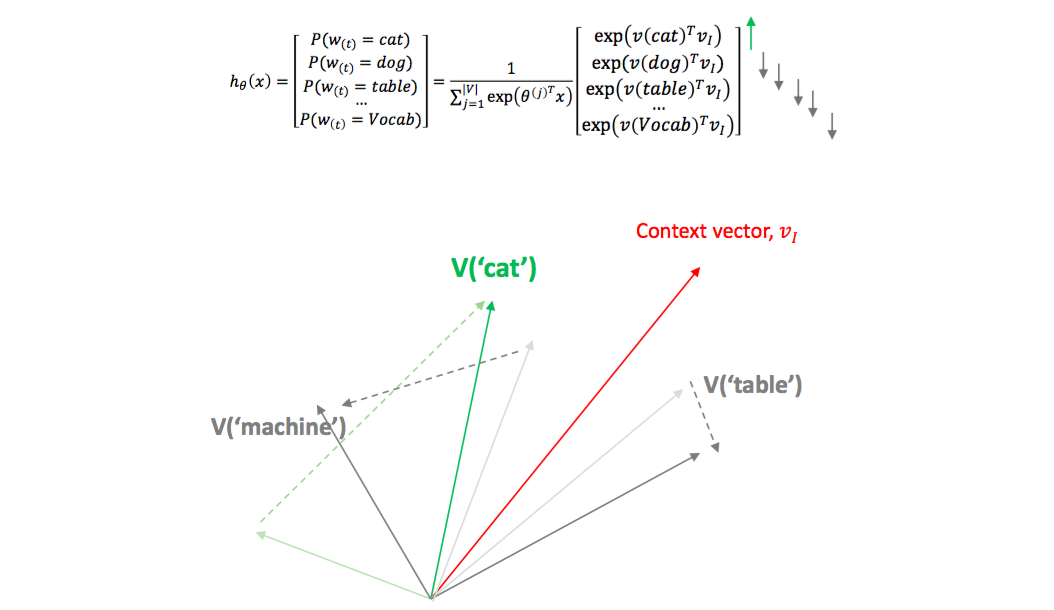
lovit님은 ‘cat’ 벡터는 context-vector와의 유사도를 늘리고, 다른 의미를 갖는 벡터들은 밀어낸다고 표현했는데 위 그림을 보면 무슨 느낌인지 감이 오실 것 같습니다.
Negative Sampling
하지만 위 공식대로 cat을 context-vector 방향으로 당겨오고, 다른 단어를 모두 밀어내려면 학습량이 엄청납니다.(모든 단어의 개수만큼 시행해야 하니까요!)
softmax regression입장에서, 충분히 떨어진 단어는 영향력이 적다고 합니다.
exp(-1)이나 exp(-10)의 크기는 exp(10)과 비교해서 둘 모두 무시할만큼 작습니다.
그렇다면 ‘밀어내는’ 행위 보다는 ‘당겨오는’ 행위에 집중해 봅시다.
중요한 것은 ‘cat’을 context-vector 방향으로 당겨오는 것입니다.
그러므로 코퍼스의 크기만큼 모든 단어를 밀어내는 것이 아닌 몇 개만 대표로 뽑아서 context-vector의 반대 방향으로 밀어냅시다. 이를 negative sampling이라고 합니다.
‘cat’은 positive sample, 다른 단어들은 negative sample입니다.
Negative sample은 각 단어의 빈도수를 고려해야 합니다.
자주 등장한 단어를 높은 확률로 선택되도록 샘플링 확률을 만듭니다.
자주 등장한 단어 만큼은 제대로 학습하려고 합니다.
수식은 크게 중요하지 않지만, 빈도수를 고려해 샘플링을 한다는 점이 중요합니다.
위 그림에서 negative sample로 ‘dog’이 선택될 수도 있습니다. 직관적으로 ‘cat’과 ‘dog’은 비슷한 벡터여야 하는데, negtaive sample로 선택되면 ‘cat’과 ‘dog’이 서로 멀어집니다.
하지만 단어가 워낙 많기 때문에 ‘dog’이 ‘cat’의 negative sample로 선택될 가능성은 적습니다.
또한 위에 말했듯 우리는 ‘당겨오는’ 행위에 집중하기 때문에, negative sample과 positive sample의 이동량이 다릅니다.
‘cat’을 context-vector 주위로 강하게 당기고, ‘dog’을 조금만 밀어 냅니다. ‘dog’이 아닌 ‘table’과 같은 단어라면 본인이 위치할 자리로 어차피 언젠가 ‘당겨지기’ 때문에 괜찮습니다.
Comments