
Keyword Analysis
17 Jul 2020 | keyword LDAKeyword Analysis
Word cloud
워드클라우드는 문서내의 빈도 수가 높은 단어를 시각화 해주는 기법입니다.
문서의 키워드, 개념 등을 직관적으로 파악할 수 있다는 장점이 존재합니다.
저희가 사용한 데이터는 카카오톡 대화 기록인데, 대화 기록은 구어체로 이루어져 있기 때문에 유의미한 키워드를 도출하기 위해서는 문어체로 작성된 문서에 비해 전처리가 좀 더 많이 필요합니다.
'ㅎㅎ 좋네요 잘되셨으면 좋겠습니다~~',
'ㅠㅅㅠ 예 이번엔 꼭 잘 해보려구여.',
'네네 ㅎㅎ 작년에 모각캐 행사했을 때, 우리 커뮤니티 스터디 분들이 다같이 오신적이 있었는데 다음 행사 때 다같이 오시면 좋겠네요',
'화이팅입니다!!',
'우왕 ^^ 그러면 재밌겠네요. 예 화이팅입니다. ㅎㅎ',
'넵넵 ㅎㅎ',
'응원합니다!! ㅎㅎ',
'ㅠㅅㅠ 으윽 이번엔 진짜. 감사합니다.',
'온라인 스터디는 다들 어떻게 하시는지 노하우가 궁금하네요!ㅎㅎ',
우선 전처리는 3 가지 과정을 거쳐서 진행됩니다.
- 오픈채팅방 이라는 특수성 때문에 생기는 출입 기록 및 사진 삭제
- 정규식, 불용어 리스트를 이용한 의미 없는 단어 제거 (e.g. 이모티콘, 한자리 숫자, 영단어 etc..)
- 2글자 이상의 명사 추출
저희가 사용한 단톡방 데이터는 약 1000여명이 사용하는 기술 커뮤니티입니다.
때문에 굉장히 많은 유저 출입이 발생하고, 그로 인해 출입 기록 데이터와, 사진 기록만 지우게 되어도 약 15,000여 데이터 중 1,000여개가 삭제됩니다.
>>>print('origin data length:',len(data))
origin data length: 15721
>>>print('Data length after preprocessing:',len(data))
Data length after preprocessing: 14700
한글은 굉장히 어려운 문법 체계를 갖추고 있습니다.
영어의 경우 띄워 쓰기만 잘 해도 품사 추출이 굉장히 쉽지만 한글은 그렇지 않습니다.
한글의 경우 띄워 쓰기 자체가 굉장히 어려운 문법 이기 때문에 오픈톡방에서 지키는 사람을 찾는 것은 쉽지 않습니다.
그렇기 때문에 불용어를 굉장히 처리하기 난감합니다.
그래서 저희는 임의의 불용어 리스트를 직접 만들어서 사용합니다.
>>>print('stop_words length:',len(stop_words))
stop_words length: 713
- 아래는 불용어 리스트의 예시(약 713개)
['정말', '이걸', '대부분', '원래', '저희', '그 때', ...]
한글의 경우 한 글자 명사에는 큰 의미가 없는 경우가 많다고 판단해서 두 글자 이상의 명사만 추출하였습니다.
- 모든 전처리를 거치고 난 후의 데이터
{'파이썬': 558,'데이터': 369,'코드': 351,'문제': 269,'사용': 264,'함수': 254,'질문': 239,
'파일': 217,'방법': 214,'공부': 209,'생각': 200,'모델': 164,'말씀': 158,'코딩': 158,
'실행': 155,'설치': 152,'가능': 149,'에러': 149,'오류': 149,'경우': 136,'이해': 127,
'출력': 127,'러닝': 123,'변수': 119,'클래스': 117,'결과': 112,'정도': 110,'리스트': 109,
'필요': 105,'확인': 104,'입력': 104,'이름': 101,'설정': 96,'이미지': 96,'관련': 95,
'경로': 95,'시작': 93,'답변': 92,'해결': 92,'언어': 90,'검색': 88,'추천': 87,'강의': 86,
'저장': 85,'모듈': 82,'자료': 81,'학습': 78,'사람': 78,'참고': 76,'토치': 76,'차이': 75,
'구현': 75,'환경': 74,'때문': 73,'라이브러리': 73,'분석': 71,'설명': 70,'이유': 69,
'회사': 68,'도움': 67,'프로그램': 67,'개발': 66,'알고리즘': 64,'처음': 64,'머신': 63,
'논문': 62,'메모리': 62,'정보': 61,'걸로': 60,'자체': 60,'이용': 59}
단어 옆의 숫자는 그 단어의 빈도 수 입니다.
기술 커뮤니티라는 특수성 때문에 대부분의 키워드가 기술과 관련된 것들이 많습니다.
- 워드 클라우드 라이브러리를 통한 시각화

Latent Dirichlet Allocation
토픽 모델링은 문서의 집합에서 토픽을 찾아내는 프로세스를 뜻합니다.
이는 검색 엔진, 고객 민원 시스템 등과 같은 문서의 주제를 알아내는 일이 중요한 곳에서 사용됩니다.
LDA(Latent Dirichlet Allocation)은 대표적인 토픽 모델링의 알고리즘입니다.
DTM(Doc-term-Matrix)을 만들고 LDA를 수행합니다.
1. Introduction
우선 LDA 모델을 블랙박스로 보고 LDA에 문서 집합을 입력하면 어떤 결과를 보여주는지 간소화된 예시를 들어봅니다.
doc1 : 저는 사과랑 바나나를 먹어요
doc2 : 우리는 귀여운 강아지가 좋아요
doc3 : 저의 깜찍하고 귀여운 강아지가 바나나를 먹어요.
LDA를 수행할 때 문서 집합에서 토픽이 몇 개가 존재할지 가정하는 것은 전적으로 사용자의 역할입니다.
모델이 학습을 통해 파라미터 값을 찾는게 아닌 사람이 임의로 설정 해줘야 하는 파라미터를 hyperparameter 라고 합니다.
그러므로 토픽의 개수 $k$ 는 하이퍼 파라미터 입니다.
우리의 예시에서는 LDA에게 2개의 토픽을 찾아달라고 요청해봅시다.
LDA에 입력으로 들어가는 DTM은 위의 워드 클라우드 때 처럼 전처리를 거친 데이터라고 가정하겠습니다.
LDA는 각 문서의 토픽 분포와 토픽 내의 단어 분포를 추정합니다. ← key point!
- 각 문서의 토픽 분포
doc1 : Topic A 100%
doc2 : Topic B 100%
doc3 : Topic B 60%, Topic A 40%
- 각 토픽의 단어 분포
Topic A : 사과 20%, 바나나 40%, 귀여운 0%, 강아지 0%, 깜찍하고 0%, 좋아요 0%
Topic B : 사과 0%, 바나나 0%, 먹어요 0%, 귀여운 33%, 강아지 33%, 깜찍하고 16%, 좋아요 16%
LDA는 토픽의 제목을 정해주지 않지만, 이 시점에서 알고리즘의 사용자는 위 결과로 부터 두 토픽이 각각 과일에 대한 토픽과 강아지에 대한 토픽이라고 판단할 수 있습니다.
Assumption
앞서 말했듯, LDA는 문서의 집합으로 부터 어떤 토픽이 존재하는지를 알아내기 위한 알고리즘입니다.
LDA는 앞서 배운 빈도수 기반의 표현 방법인 BoW, DTM, TF-IDF를 입력으로 하는데, 여기서 알 수 있는 점은 LDA는 “단어의 순서”는 신경 쓰지 않습니다.
각 문서는 다음과 같은 과정을 통해 작성 되었다고 가정합니다.
- 각 문서에 사용할 단어의 개수 $N$을 정한다.
- 문서에 사용할 토픽의 혼합을 확률 분포에 기반 하여 결정한다.(e.g. 강아지 토픽 60%, 과일 토픽 40%)
- 문서에 사용할 각 단어를 결정한다.
- 토픽 분포에서 토픽 $T$를 확률적으로 고른다.
- 선택한 토픽에서 단어 출현 확률 분포에 기반 하여 문서에 사용할 단어를 고른다.
Execute
이제 수행 과정을 정리해봅시다.
- 사용자는 모델에게 토픽의 개수 $(k)$를 알려준다 ← $k$ is a hyperparameter
- 모든 단어를 $k$개 중 하나의 토픽에 할당한다.
- LDA가 모든 문서의 모든 단어에 대해 $k$개 중 하나의 토픽을 랜덤으로 할당합니다.이 작업이 끝나면 각 문서는 토픽을 가지게 되며, 토픽은 단어 분포를 가지는 상태이다. 물론 랜덤으로 할당하였기 때문에 이 결과는 대부분 틀린 상태이다. 만약 한 단어가 문서에 2회이상 등장 하였다면, 서로 다른 토픽에 할당 되었을 수도 있다.
- 이제 모든 문서의 모든 단어에 대해 아래의 사항을 반복 진행한다.
- 어떤 문서의 각 단어 $w$는 자신은 잘못 된 토픽에 할당 되어 있지만, 다른 단어들 전부 올바른 토픽에 할당 되어진 상태라고 가정하자. 이에 따라 단어 w는 아래의 두 가지 기준에 따라 토픽이 재할당 된다.
- $p(topic(t)\vert documet(d))$: 문서 $d$의 단어들 중 토픽 $t$에 해당하는 단어들의 비율
- $p(word(w)\vert topic(t))$: 단어 $w$를 갖고 있는 모든 문서들 중 토픽 $t$가 할당된 비율
- 어떤 문서의 각 단어 $w$는 자신은 잘못 된 토픽에 할당 되어 있지만, 다른 단어들 전부 올바른 토픽에 할당 되어진 상태라고 가정하자. 이에 따라 단어 w는 아래의 두 가지 기준에 따라 토픽이 재할당 된다.
쉽게 풀어서 얘기 해보자.
우선 토픽이 임의의 문서 $d_t$에 존재하는 단어 $w$에 토픽을 할당하려고 한다.
- 단어 $w$가 속한 문서에서 다른 단어들에 할당된 토픽을 본다.
- 현재 문서 $d_t$에서 동일한 단어 $w$에 할당된 토픽과 다른 문서 $(d_1,…,d_n)$ 에서 동일한 단어 $w$에 할당된 토픽들을 본다.
Conclusion
LDA는 한마디로 말하면 단어가 특정 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합 확률로 추정하여 토픽을 추출합니다.
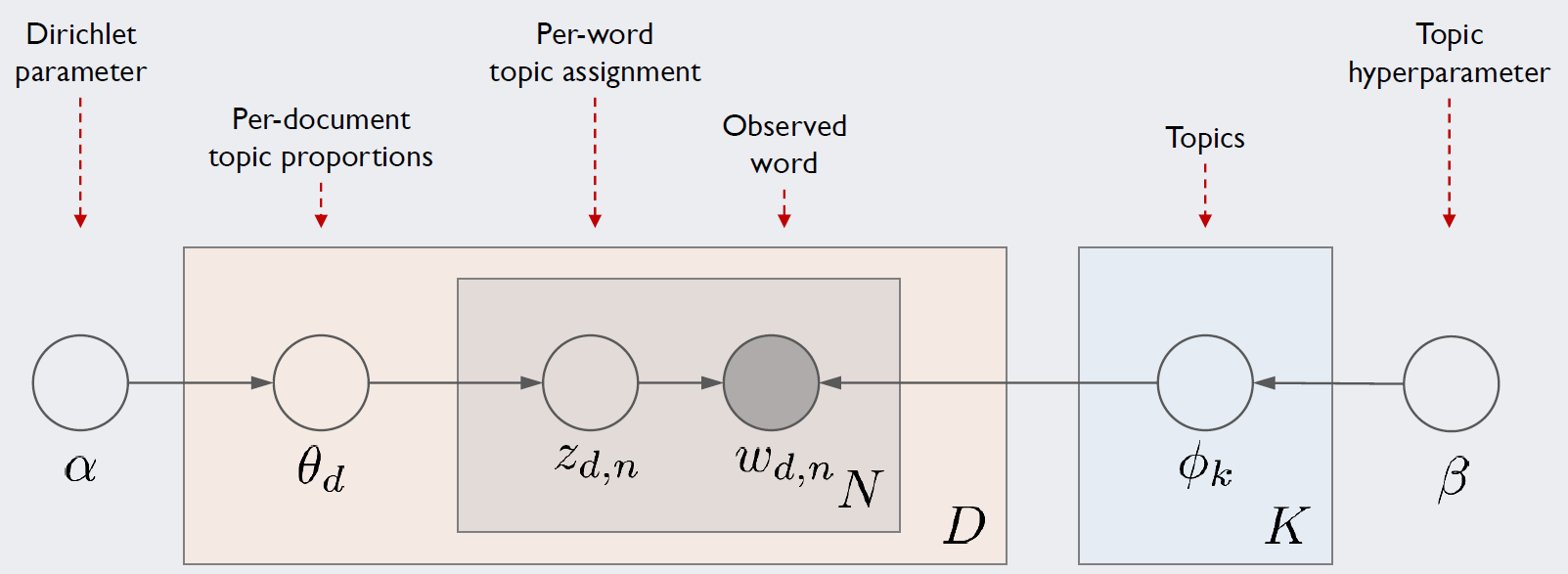
LDA에서 각 토픽에 할당된 모든 단어들의 확률을 합하면 1이되고,
각 문서에서 토픽들이 할당된 확률을 모두 합해도 1이됩니다. → 이래서 이름에 Dirichlet 가 들어갑니다.
우리의 모델로 돌아갑시다!
우리는 단톡방 데이터를 사용하고 → 전처리는 이미 워드 클라우드를 통해 끝났습니다.
다만 앞서 언급했듯 LDA모델의 인풋에는 DTM이 필요하기 때문에 DTM 포맷으로 만들어주고 Gensim 라이브러리에 구현된 모델을 불러와서 구현해보겠습니다.
dictionary = corpora.Dictionary([keywords[0]])
dictionary.add_documents([keywords[1],keywords[2]])
#dictionary = DTM
%%time
train = keywords[0]+keywords[1]+keywords[2]
corpus = [dictionary.doc2bow([text]) for text in train]
ldamodel = models.ldamodel.LdaModel(corpus, num_topics=10, id2word = dictionary, passes=20)
#ldamodel이 우리의 모델입니다!
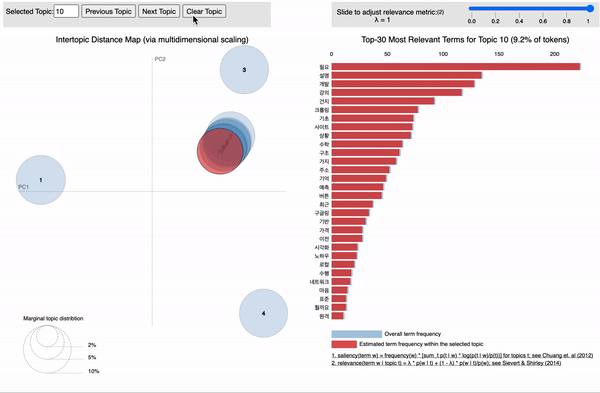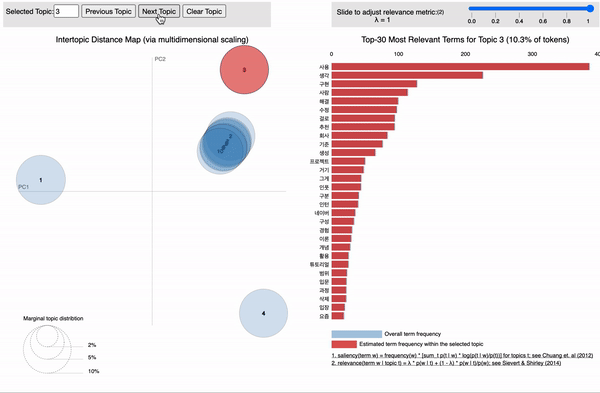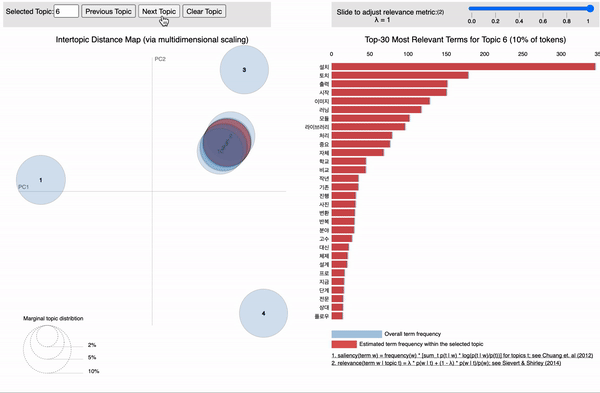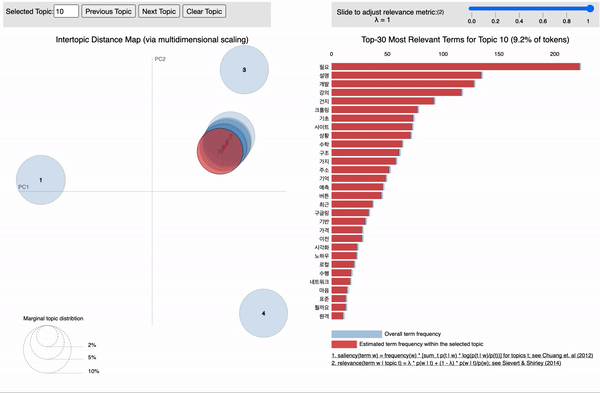
아까 토픽 들은 각 단어 들에 확률 분포 형태로 매핑 된다고 했습니다.
각 토픽에 할당된 단어들을 확률이 높은 순서대로 상위 5개씩 보여주는 코드입니다.
topics = ldamodel.print_topics(num_words=5)
[topic for topic in topics]
[(0, '0.147*"문제" + 0.090*"공부" + 0.067*"실행" + 0.048*"가상" + 0.040*"입력"'),
(1, '0.140*"모델" + 0.084*"정도" + 0.063*"가능" + 0.057*"성능" + 0.047*"결과"'),
(2, '0.198*"파이썬" + 0.102*"방법" + 0.100*"질문" + 0.057*"설정" + 0.036*"차원"'),
(3, '0.141*"사용" + 0.083*"생각" + 0.047*"구현" + 0.042*"사람" + 0.036*"해결"'),
(4, '0.089*"말씀" + 0.076*"경우" + 0.075*"배치" + 0.063*"패키지" + 0.054*"답변"'),
(5, '0.154*"데이터" + 0.103*"함수" + 0.094*"환경" + 0.056*"이용" + 0.049*"때문"'),
(6, '0.091*"필요" + 0.055*"설명" + 0.052*"개발" + 0.048*"강의" + 0.038*"건지"'),
(7, '0.125*"파일" + 0.072*"에러" + 0.067*"학습" + 0.054*"관련" + 0.041*"검색"'),
(8, '0.131*"설치" + 0.068*"토치" + 0.057*"출력" + 0.057*"시작" + 0.049*"이미지"'),
(9, '0.206*"코드" + 0.066*"오류" + 0.058*"윈도우" + 0.045*"차이" + 0.043*"변수"')]
#각 단어들 앞에 숫자가 확률값입니다!
Comments